前言
论文:https://arxiv.org/pdf/1908.10084.pdf
代码:https://github.com/UKPLab/sentence-transformers
摘要
BERT和RoBERTa在句子对回归任务,如语义文本相似度(STS)上取得了新的最先进的性能。然而,它需要将两个句子都输入到网络中,这会导致巨大的计算开销:使用BERT在10,000个句子的集合中找到最相似的一对,需要大约5000万次推理计算(~65小时)。BERT的构造使其不适合语义相似性搜索以及聚类等无监督任务。
论文提出sentence -BERT (SBERT),一种预训练BERT网络的修改,使用孪生和三元网络结构来得到有语义的句子嵌入,可以用余弦相似度进行比较。这将寻找最相似的一对的工作量从BERT / RoBERTa的65小时减少到SBERT的大约5秒,同时保持BERT的准确性。
在常见的STS任务和迁移学习任务上评估了SBERT和SRoBERTa,其表现优于其他最先进的句子嵌入方法。
动机
BERT使用交叉编码器:将两个句子传递给transformer网络,并预测目标值。然而,由于可能的组合太多,这种设置不适合各种对回归任务。有些任务到目前为止并不适用于BERT。这些任务包括大规模的语义相似性比较、聚类和基于语义搜索的信息检索。
解决聚类和语义搜索的一种常见方法是将每个句子映射到向量空间,使语义相似的句子接近。研究人员已经开始将单个句子输入到BERT中,并获得固定大小的句子嵌入。最常用的方法是平均BERT输出层(称为BERT嵌入)或使用第一个标记的输出([CLS]标记)。但是,这种常见做法产生了相当糟糕的句子嵌入,通常比平均GloVe嵌入更糟糕。
解决方法
为了缓解这个问题,作者开发了SBERT。孪生网络架构使输入句子的固定大小的向量可以推导出来。使用余弦相似度或曼哈顿/欧几里得距离等相似性度量,可以找到语义相似的句子。这些相似性度量在现代硬件上可以非常高效地执行,使SBERT可以用于语义相似性搜索和聚类。
在NLI数据上对SBERT进行微调,创建的句子嵌入显著优于其他最先进的句子嵌入方法,如InferSent和Universal sentence Encoder。在7个语义文本相似度(STS)任务上,SBERT比InferSent提高了11.7分,比Universal Sentence Encoder提高了5.5分。在句子嵌入评估工具包SentEval上,分别取得了2.1和2.6分的提升。
模型
SBERT向BERT / RoBERTa的输出添加了池化操作,以导出固定大小的句子嵌入。用三种池化策略进行了实验:使用CLS-token的输出;计算所有输出向量的平均值(MEAN-strategy),以及计算输出向量的最大值(MAX-strategy)。默认配置为MEAN。
为了微调BERT / RoBERTa,创建了孪生网络和三元网络来更新权重,使生成的句子嵌入具有语义意义,并可以与余弦相似度进行比较。网络结构取决于可用的训练数据。用以下结构和目标函数进行实验。
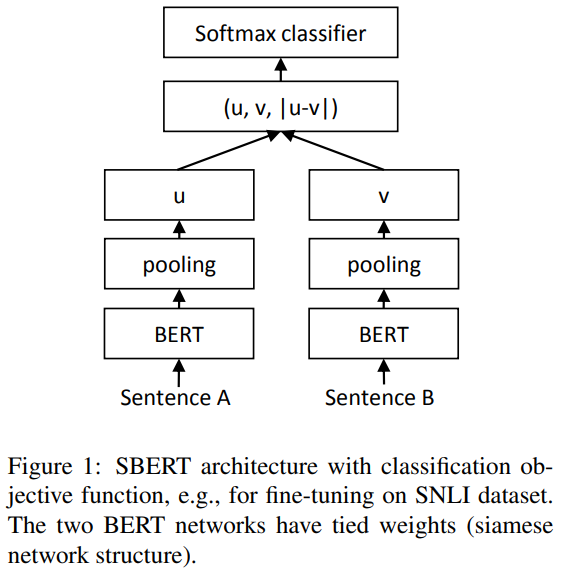
分类目标函数
将句子嵌入u和v与元素差异|u−v|连接起来,并将其与可训练权重Wt∈R3n×k相乘:
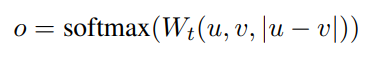
其中n是句子嵌入的维度,k是标签的数量。优化交叉熵损失。这个结构如图1所示:
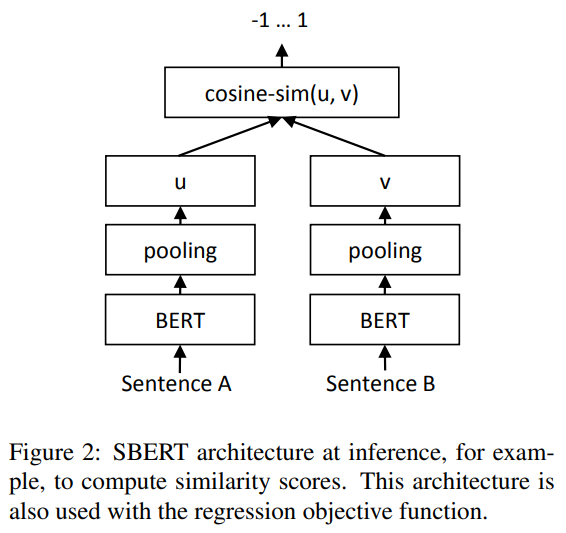
回归目标函数
计算两个句子嵌入u和v之间的余弦相似度(图2)。使用均方误差损失作为目标函数。
三元组目标函数
给定一个锚句子a、一个正句子p和一个负句子n,三元组损失调整网络,使a和p之间的距离小于a和n之间的距离。在数学上,最小化以下损失函数:
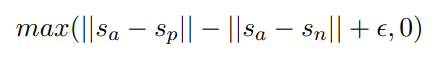
结论
BERT开箱即用,将句子映射到向量空间,不适合与常见的相似性度量(如余弦相似度)一起使用。7个STS任务的性能低于平均GloVe嵌入的性能。
为了克服这个缺点,提出了Sentence-BERT (SBERT)。SBERT在孪生/三元组网络架构中对BERT进行微调。在各种常见基准上评估了质量,与最先进的句子嵌入方法相比,它可以实现显著的改进。用RoBERTa替换BERT并没有在论文的实验中产生显著的改进。
SBERT的计算效率很高。在GPU上,它比InferSent快约9%,比Universal Sentence Encoder快约55%。SBERT可用于计算上不可用BERT建模的任务。例如,使用层次聚类对10,000个句子进行聚类需要BERT大约65小时,因为必须计算大约5000万个句子组合。使用SBERT,可以将时间缩短到5秒左右。