前言
论文:https://aclanthology.org/2022.acl-long.570.pdf
代码:https://github.com/amazon-research/label-aware-pretrain
摘要
在文本分类任务中,有用的信息编码在标签名称中。标签语义感知系统利用这些信息在微调和预测期间提高了文本分类性能。然而,标签语义在预训练中的应用还没有得到广泛的探讨。因此,作者提出标签语义感知预训练(LSAP)来提高文本分类系统的泛化和数据效率。LSAP通过对来自不同领域的带有标签的句子进行二次预训练,将标签语义整合到预训练生成模型中。由于预训练需要大量的数据,作者开发了一个过滤和标注pipline来自动从未标记的文本创建sentence-label对。
模型架构
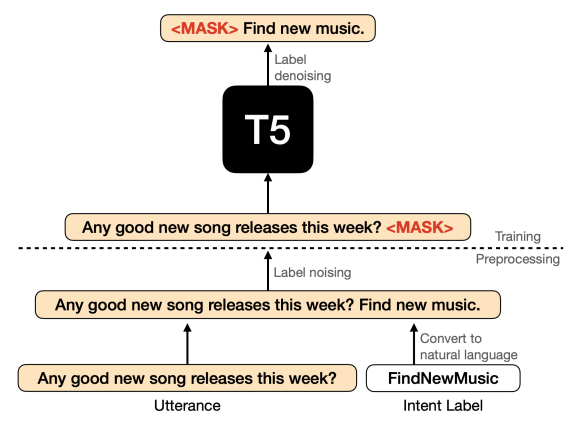
- 在预训练阶级将标签语义融入生成模型的方法。
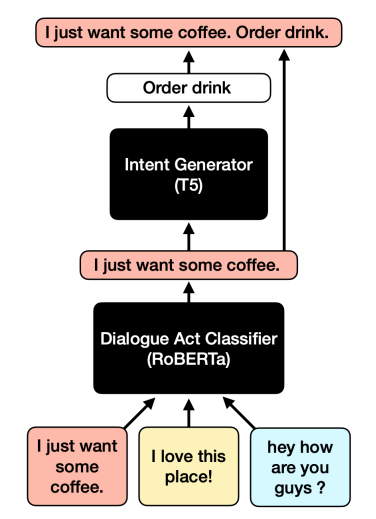
- 一种从无标记噪声数据中为标签语义感知预训练创建话语-意图对的方法。
方法
LSAP方法在(伪)标记样本的大规模集合上使用T5进行二次预训练。
- 使用对话行为分类器(dialogue act classifier)过滤未标记的数据。
- 使用意图生成器(intent generator)对通过过滤器的话语进行伪标记。
- 使用T5对标记数据和伪标记数据进行二次预训练
Pre-training Formats
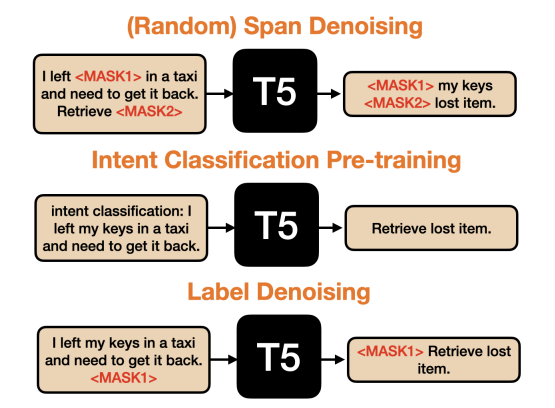
- Random span denoising,将每个意图标签(以自然语言格式)连接到其相关的话语。然后,我们随机干扰语音意图输入序列中15%的tokens,重建输出序列中连续的noised spans。这与T5使用的目标相同。
- Intent classification,用下游监督微调使用的相同格式的话语和意图来监督微调T5。在这里,输入顺序是“intent classification: ”,然后是话语。输出序列是目的。
- Label denoising,在训练话语和它们各自的意图前,确定性地对输入序列中的整个标签序列进行噪声化,并在输出序列中重构它。这是一种将意图分类任务框定为无监督去噪任务的方法。
总结
提出了一种利用标签中固有语义信息的预训练方法。提高了跨域小样本文本分类性能,同时在全资源设置下保持高性能。