前言
论文:https://arxiv.org/pdf/2108.13161.pdf
代码:https://github.com/zjunlp/DART
动机
优化prompt是提高预训练语言模型在小样本学习中是很有必要的。离散标记的模板可能陷入局部最优,并且不能充分表示特定的类别。为了提高prompt方法在各个领域的适用性,论文提出了可微分提示(DifferentiAble pRompT),简称DART,可以减少提示工程的要求。
模型框架
利用语言模型中的一些参数作为模板和标签标记,并通过反向传播对它们进行优化,而不引入模型之外的其他参数。因为有限样本的微调可能会受到不稳定性的影响。进一步引入了一个辅助流畅性约束对象,以确保prompt嵌入之间的关联。减少提示工程(包括模板和标签)和外部参数优化。此外,该算法可以使用任何预训练的语言模型并可扩展到广泛的分类任务。
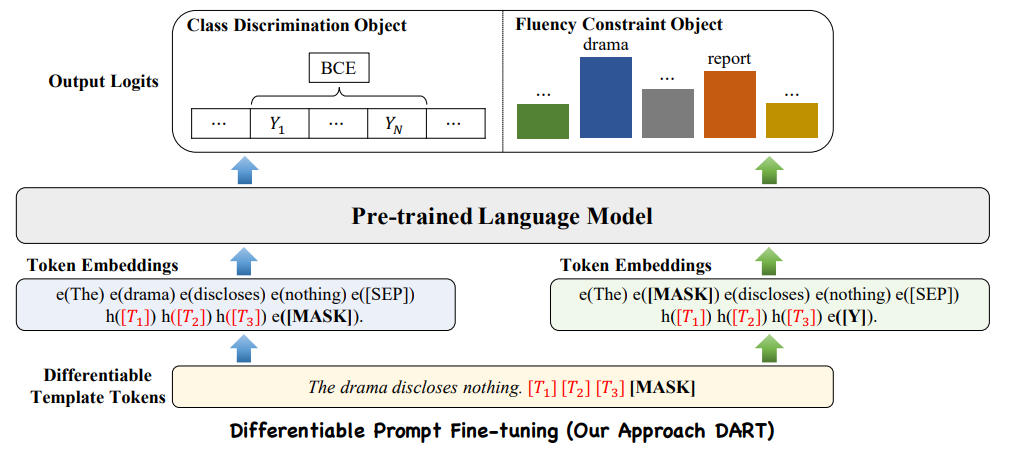
Differentiable Template Optimization
由于语言token是离散变量,用token搜索找到最优提示并不简单,很容易陷入局部极小值.为了克服这些限制,作者利用伪标记(pseudo tokens)构造模板,然后用反向传播优化它们。可微模板优化可以获得超越原始词汇V的表达模板。将模板映射为如下形式:
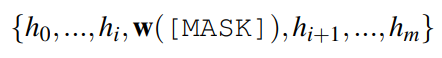
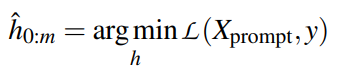
DART利用辅助流畅性约束目标将提示嵌入彼此关联起来,从而促进模型专注于上下文表示学习。
Differentiable Label Optimization
暴力强制标签搜索:(1)由于验证集通常非常大,需要进行多轮评估,计算量大且繁琐。(2)可扩展性差,随着类数的增加呈指数型增长,因此很难处理。此外,类别的标签包含丰富而复杂的语义知识,一个离散的标记可能不足以表示这些信息。
DART将Yj映射到一个连续词汇空间,如下所示:
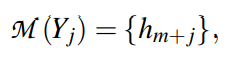
为了避免优化任何外部参数,{h1,…,hm,..,hm+n}替换为未使用的token
Training Objectives
由于提示模板中的伪标记必须彼此相互依赖,作者引入了辅助的流畅性约束训练,而没有优化任何其他参数。总体而言,有两个目标:the class discrimination objective(LC)和the fluency constraint objective(LF)
Class Discrimination Objective
是对句子进行分类的主要目标,CE是交叉熵损失函数。
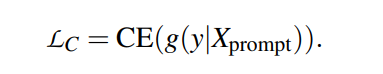
Fluency Constraint Objective
为了确保模板标记之间的关联,并维护从PLMs继承来的语言理解能力,作者利用MLM的流畅性约束对象,对输入语句中的一个标记进行随机掩码,并进行掩码语言预测。该语言模型可以通过模板标记之间的丰富关联获得更好的上下文表示。
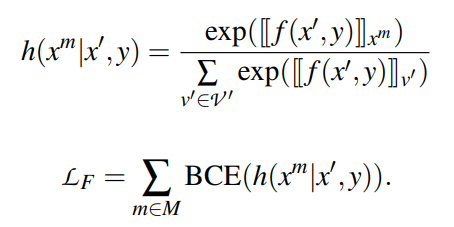
为了小样本微调的不稳定性,作者联合优化模板和标签。
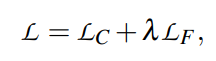
结论
论文介绍了一种简单而有效的优化方法DART,它改进了fast-shot learning预训练语言模型。与传统的优化方法相比,所提出的方法可以在小样本的情况下产生令人满意的改进。该方法还可用于其他语言模型(如BART),并可扩展到其他任务,如意图检测和情感分析。