前言
论文:https://arxiv.org/pdf/1902.08050.pdf
代码:https://github.com/AIRobotZhang/STCKA
摘要
短文本分类是自然语言处理(NLP)中的重要任务之一。与段落或文档不同,短文本由于没有足够的上下文信息而更加模糊,这对分类提出了很大的挑战。论文通过从外部知识源检索知识来增强短文本的语义表示。将概念信息作为一种知识,并将其纳入深度神经网络。为了度量知识的重要性,引入了注意机制,并提出了基于知识驱动注意的短文本深度分类(STCKA)。利用概念对短文本(CST)的注意和概念对概念集(C-CS)的注意,从两个方面获取概念的权重。并利用概念信息对短文本进行分类。与传统方法不同的是,STCKA模型就像一个人一样,具有基于观察(即机器的训练数据)做出决策的内在能力,并且更加关注重要的知识。还针对不同的任务在四个公共数据集上进行了广泛的实验。实验结果和案例研究表明,STCKA模型优于最先进的方法,证明了知识驱动注意力的有效性。
挑战
挑战1
相对于段落或文档,短文本由于缺乏足够的上下文信息而具有更强的歧义性,这给短文本分类带来了巨大挑战。短文本分类主要可以分为显式表示和隐式表示两类。
- 显式模型具有可解释性,便于人类理解。然而,这种显式表示通常忽略了短文本的上下文,无法捕捉深层语义信息。
- 基于深度神经网络的隐式模型擅长捕捉短文本中的语法和语义信息。然而,它忽略了知识库中存在的isA、isPropertyOf等重要的语义关系。这些信息有助于理解短文本,特别是在处理未见过的单词时。
该文将短文本的显式和隐式表示融合到一个统一的深度神经网络模型中。在YAGO和Freebase等显式KBs的帮助下丰富了短文本的语义表示。这允许模型从短文本中没有明确声明但与分类相关的外部知识源检索知识。概念信息作为一种知识对分类是有帮助的。因此,该文利用isA关系,将短文本与知识库中的相关概念进行概念化关联。然后,将概念信息作为先验知识融入深度神经网络。
挑战2
尽管简单地将概念信息集成到深度神经网络中似乎很直观,但仍然存在两个主要问题。
- 首先,在对短文本进行概念化时,由于实体的歧义性或KBs中的噪声,容易引入一些不恰当的概念。例如,在短文本S2:“Alice has been using Apple for 10 more years”中,从KB中获取了Apple的fruit和mobile phone两个概念。显然,fruit在这里不是一个合适的概念,这是由于Apple的模糊性造成的。
- 其次,需要考虑概念的粒度和概念的相对重要性。例如,在短文本S3:“Bill Gates is one of the co-founders of Microsoft”中,从KB中检索了person和entrepreneur of Bill Gates的概念。虽然它们都是正确的概念,但企业家比人更具体,在这种情况下应该被赋予更大的权重。之前的工作利用网络规模的KBs来丰富短文本表示,但没有仔细解决这两个问题。
为了解决这两个问题,该文引入注意力机制,提出了基于知识驱动注意力的深度短文本分类(STCKA)。注意力机制被广泛用于获取向量的权重,在许多NLP应用中,包括机器翻译、摘要生成和问答。针对第一个问题,使用面向短文本的概念注意力(Concept towards Short Text,CST)来衡量短文本与其对应概念之间的语义相似度。该模型赋予S2中mobile phone概念较大的权重,因为它与短文本的语义相似度高于fruit概念。针对第二个问题,使用面向概念集的注意力(Concept towards Concept Set,C-CS)来探索每个概念相对于整个概念集的重要性。模型为S3中的概念企业家分配了更大的权重,这对特定的分类任务更具区分性。
引入一种软开关(soft switch)来将两个注意力权重组合为一个,并产生每个概念的最终注意力权重,该模型在不同的数据集上自适应地学习。然后对概念向量进行加权求和,得到概念表示;此外,充分利用短文本的字和词两级特征,并利用自注意力机制生成短文本表示;最后,根据短文本的表示及其相关概念对短文本进行分类。
模型
STCKA是一个知识增强的深度神经网络,如图所示。网络的输入是一个短文本s,它是一个单词序列。网络的输出是类标签的概率分布。用p(y|s,φ)表示短文本属于类别y的概率,其中φ是网络中的参数。模型包含四个模块。
- 知识检索模块从知识库中检索与短文本相关的概念信息。
- 输入嵌入模块利用短文本的字和词级别特征生成词和概念的表示。
- 短文本编码模块通过自注意力机制对短文本进行编码并产生短文本表示q。
- 知识编码模块将两种注意力机制应用于概念向量以获得概念表示p。
然后,将p和q连接起来以融合短文本和概念信息,并将其送入全连接层。最后,使用输出层来获取每个类别标签的概率。
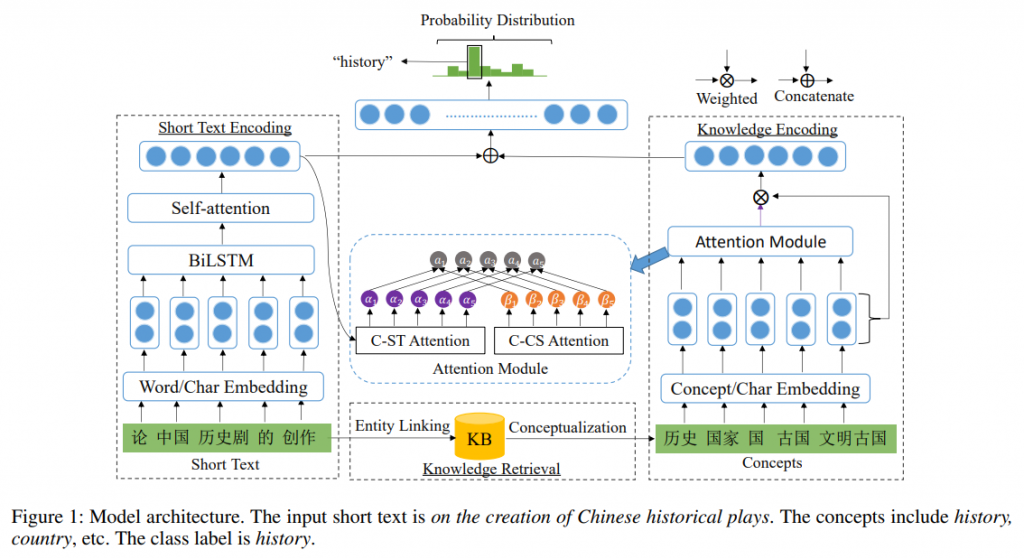
知识检索(Knowledge Retrieval)
该模块的目标是从KBs中检索相关知识。文中以isA关系为例,其他语义关系如isPropertyOf也可以采用类似的方法进行应用。具体来说,给定一个短文本s,希望找到一个与它相关的概念集C。通过两个主要步骤来实现这一目标:实体链接和概念化。通过利用现有的实体链接解决方案获得短文本的实体集E。然后,对于e∈E的每个实体e,从现有的知识库中获取其概念信息,如YAGO、Probase和CNProbase。例如,给定一篇短文本“Jay and Jolin are born in Taiwan”,通过实体链接得到实体集合E = {Jay Chou, Jolin Tsai}。然后,对Jay Chou进行概念化,从CN-Probase中获取Jay Chou的概念集C = {person, singer, actor, musician, director}。
输入嵌入(Input Embedding)
输入由两部分组成:长度为n的短文本s和大小为m的概念集C。在该模块中使用了字符向量、词向量和概念向量三种嵌入向量。字符嵌入层负责将每个单词映射到高维向量空间。使用卷积神经网络(CNN)获得每个单词的字符级嵌入。将字符嵌入到向量中,可以认为向量是CNN的1维输入,其大小是CNN的输入通道大小。CNN的输出在整个宽度上进行最大池化,以为每个单词获得固定大小的向量。词和概念嵌入层还将每个词和概念映射到高维向量空间。我们使用预训练的词向量(word2vec)来获得每个单词的词嵌入。词向量、字向量和概念向量的维数均为d/2。将字符嵌入向量和词/概念嵌入向量连接起来得到d维的词/概念表示。
短文本编码(Short Text Encoding)
该模块的目标是为长度为n的给定短文本生成短文本表示q,该短文本表示为d维词向量序列(x1, x2,…xn)。自注意力是注意力机制的一种特殊情况,只需要一个序列来计算其表示。在使用self-attention之前,添加一个循环神经网络(RNN)来转换来自底层的输入。原因解释如下,注意力机制使用加权和来生成输出向量,因此其表征能力有限。同时,RNN擅长捕捉序列的上下文信息,可以进一步增强注意力网络的表达能力。
在论文中,采用双向LSTM (BiLSTM)来处理短文本,由前向网络和后向网络组成:
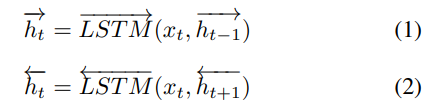
将每个前向和后向连接起来,得到一个隐藏状态ht。设每个单向LSTM的隐单元数为u。为简单起见,我们将所有hts表示为H∈Rn×2u:
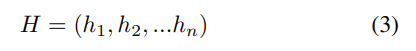
然后,使用缩放点积(scaled dot-product)注意力,这是点积(乘性)注意力的一种变体。目的是学习句子中单词的依赖关系,捕捉句子的内部结构。给定一个由n个查询向量(query vectors)Q∈Rn×2u,keys K∈Rn×2u和values V∈Rn×2u组成的矩阵,缩放点积注意力根据以下等式计算注意力得分:
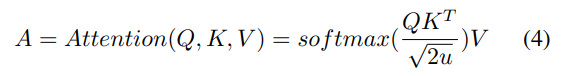
这里Q、K和V是同一个矩阵,等于H。注意力层的输出是一个矩阵,记为A∈Rn×2u。接下来,使用A上的max-pooling层来获取短文本表示q∈R2u。其思想是在向量的每个维度上选择最高的值来捕获最重要的特征。
知识编码(Knowledge Encoding)
从知识库等外部资源中获取的先验知识为短文本的类别标签判定提供了更丰富的信息。以概念信息为例来说明知识编码,其他先验知识也可以以类似的方式使用。给定一个大小为m的概念集C,记为(c1, c2,… , cm)其中ci是第i个概念向量,目标是产生其向量表示p。首先,引入了两种注意力机制,以更多地关注重要的概念。
为了减少由于实体的歧义性或KBs中的噪声而引入的一些不当概念的不良影响,提出了基于vanilla attention的面向短文本的概念注意力,以衡量第i个概念和短文本表示q之间的语义相似度。使用以下公式来计算C-ST注意力:

这里的αi表示第i个概念对短文本的注意力权重。较大的αi意味着第i个概念与短文本在语义上更相似。F(·)是一个非线性激活函数,如双曲正切变换,softmax用于归一化每个概念的注意力权重。W1∈Rda*(2u+d)是一个权重矩阵,w1∈Rda是一个权重向量,其中da是超参数,b1是偏移量。
此外,为了考虑概念的相对重要性,基于source2token self-attention提出了面向概念集的概念注意力,以衡量每个概念相对于整个概念集的重要性。将每个概念的C-CS注意力定义如下:
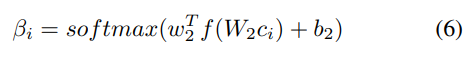
其中βi表示第i个概念对整个概念集的注意力权重。W2∈Rdb×d是一个权重矩阵,w2∈Rdb是一个权重向量,其中db是超参数,b2是偏移量。C-CS注意力的效果与特征选择类似。它是一种“软”特征选择,将较大的权重分配给重要概念,而将较小的权重(接近于零)分配给平凡概念。
通过下面的公式组合αi和βi来获得每个概念的最终注意力权重:
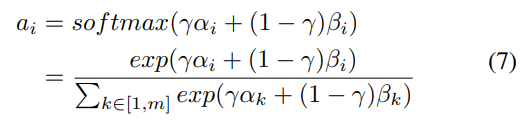
这里ai表示第i个概念对短文本的最终注意力权重,γ∈[0,1]是一个软开关,用于调整两个注意力权重αi和βi的重要性。有多种方法可以设置参数γ。最简单的一种是将γ视为一个超参数,并手动调整以获得最佳性能。或者,γ也可以由神经网络自动学习。论文选择后者,因为它在不同的数据集上自适应地为γ分配不同的值,并取得了更好的实验结果。用下面的公式计算γ:
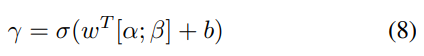
其中向量w和标量b是可学习的参数,σ是sigmoid函数。最后,利用注意力权重计算概念向量的加权和,得到表示概念的语义向量:

一般来说,对于分类来说重要的概念被赋予较大的权重,反之亦然。还发现了模型的一些特性。
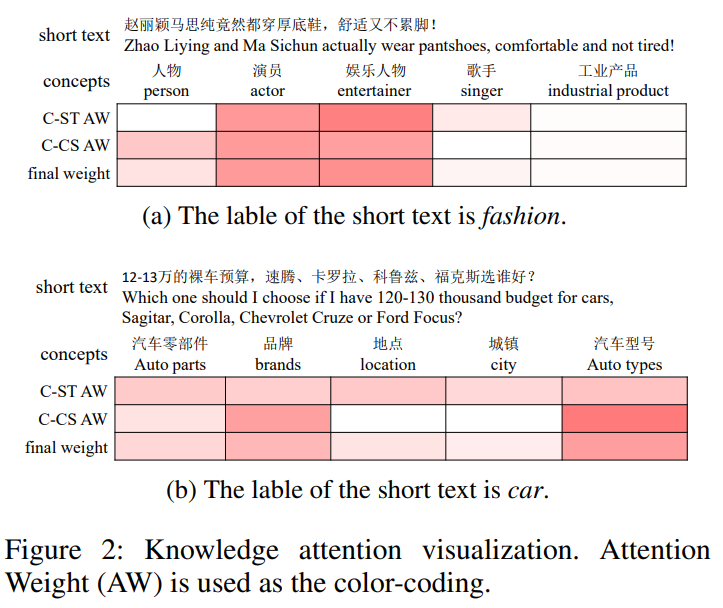
- 首先,它是可解释的。给定一篇短文本及其对应的概念,该模型通过注意力机制得到每个概念对分类的贡献。
- 其次,对噪声概念具有鲁棒性。例如,如图2a所示,在对短文本进行概念化时,获得了一些不合适的概念,如工业产品,这些概念对分类没有帮助。该模型给这些概念赋予了较小的注意力权重,因为它们与短文本无关,且与短文本几乎没有相似度。
- 第三,C-CS注意力的效果与特征选择相似。在某种程度上,C-CS注意力是一种“软”特征选择,为不相关的概念分配了较小的权重(几乎为零)。因此,C-CS注意力产生的注意力权重是稀疏的,类似于L1范数正则化。
训练(Training)
为了训练模型,将所有要训练的参数表示为一个集合φ。网络的训练目标是最大化关于φ的对数似然:
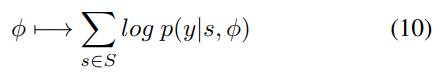
其中S是训练短文本集,y是短文本s的正确类别。
总结
论文提出一种基于知识驱动注意力的深度短文本分类方法。融合KBs中的概念信息以增强短文本的表示。为了度量每个概念的重要性,采用两种注意力机制自动获取概念的权重,并将其用于生成概念表示。根据短文本及其相关概念对短文本进行分类。最后,在4个不同任务的数据集上验证了该模型的有效性,结果表明其性能优于当前最先进的方法。未来,可以将在深度神经网络中融入属性值信息,进一步提升短文本分类的性能。研究发现,由于知识库的不完备性,短文本中提到的一些实体缺乏概念。除了概念信息,实体属性及其值也可以作为显式特征注入深度神经网络。