前言
论文:https://arxiv.org/pdf/2203.02898.pdf
代码:https://github.com/rowitzou/dc-match
摘要
文本语义匹配是一项基础任务,已被广泛应用于社区问答、信息检索和推荐等各种场景。大多数最先进的匹配模型,例如BERT,通过统一处理每个单词直接执行文本比较。但是,查询句通常包含要求不同级别匹配粒度的内容。具体来说,关键词代表事实信息,如行动、实体和事件,应该严格匹配,而意图传达抽象的概念和想法,可以转述为各种表达。在论文中,提出了一种简单有效的分而治之的文本语义匹配训练策略,将关键词与意图分离开来。该方法可以很容易地与预先训练的语言模型(PLM)相结合,而不影响它们的推理效率,在三个基准测试中,针对广泛的PLM实现稳定的性能改进。
简介
大多数现有的PLM旨在为各种下游任务建立基础,并专注于寻找一种编码文本序列的通用方法。在应用于文本语义匹配任务时,通常添加一个简单的分类目标进行微调,通过统一处理每个词直接进行文本比较。然而,每个句子通常可以被分解为具有不同匹配粒度的内容。例句对可以在图1中找到。主要内容是指反映实体或行为的事实信息的关键词,需要严格匹配。其他内容构成抽象的意图,一般可以用不同的表达方式来表达相同的概念或想法。

针对句子内容具有不同层次匹配粒度的情况,提出了一种简单而有效的分而治之的文本语义匹配训练机制DC-Match。具体地,我们将匹配问题分解为两个子问题:关键词匹配和意图匹配。给定一对输入文本序列,该模型通过利用远程监督的方法学习将关键词从意图中分离出来。
除了具有全局感受野的标准序列匹配外,进一步将关键词和意图分别进行匹配,以学习不同粒度级别下的内容匹配方式。最后,我们设计了一个特殊的训练目标,结合子问题的解,最小化全局匹配分布(原始问题)和关键词意图联合匹配分布(子问题)之间的KL散度。在推理时,我们期望全局匹配模型自动区分关键词和意图,然后根据不同匹配层次中分解的内容进行最终预测。
贡献
- 提出了一种新的文本匹配训练机制,基于不同层次的匹配粒度,以分而治之的方式将关键词从意图中分离出来。
- 所提方法简单有效,可以很容易地与PLM加上少量辅助训练参数相结合,而不改变其原始推理效率。
- 在两种语言的三个基准上的实验结果表明了所提出方法在不同方面的有效性。
方法
提出的DC-Match训练机制包括三个训练目标:
- 全局匹配模型的分类损失;
- 一种远程监督分类损失,它能学会区分关键词和意图;
- 一种遵循分而治之思想的特殊训练目标,利用KL散度(KL-divergence)保证全局匹配分布(原始问题)与分离的关键词和意图的组合解分布(子问题)相似。
总体框架如图2所示。
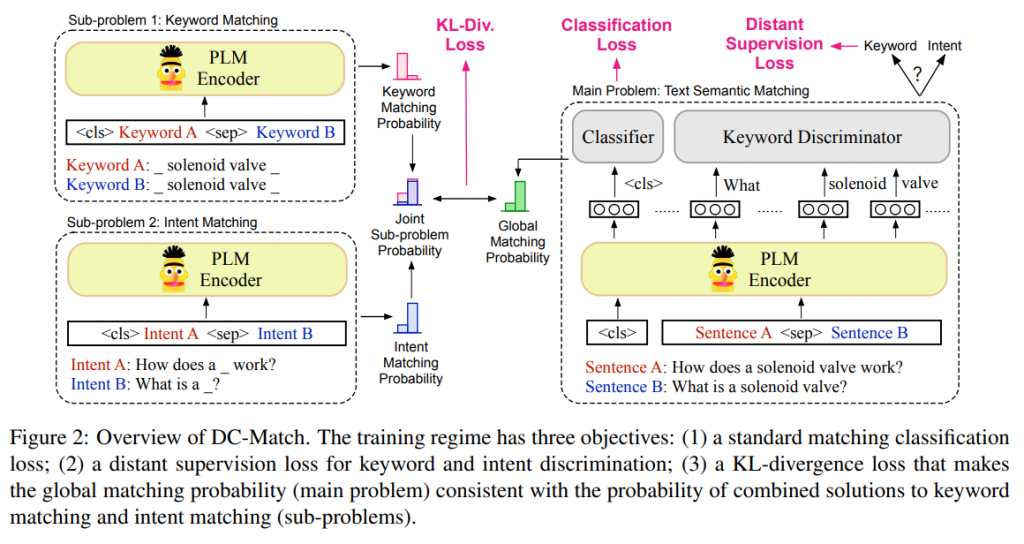
文本语义匹配
使用预训练语言模型常规的方法是将两个句子连接起来,例如[CLS]Sa[SEP]Sb输入到PLM模型编码层中:
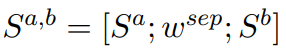
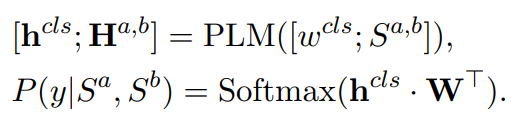
y可以是表示两个序列是否匹配的二分类目标,也可以是反映匹配程度不同的多分类目标。计算用于微调的标准分类损失如下:
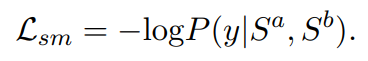
使用远程监督将关键词从意图中分离
论文对文本语义匹配引入了一个特定任务的假设,假设每个句子可以分解为关键词和意图。直观地说,关键词代表了事实信息,如应该严格匹配的动作和实体,而意图传达了可以用不同方式表达的抽象概念或想法。通过对关键词和意图的分解,将匹配过程分解为两个简单的子问题,每个子问题需要不同粒度的匹配。
然而,由于缺乏人工标注的数据,关键词和意图的自动分解并不容易。为解决这个问题,根据最近对远程监督的研究,论文使用一种基于规则的方法,基于外部知识库中的实体,通过提取原始文本中的实体提及来自动生成关键词标签。
所有抽取的实体被标记为关键词,其余的句子单词被标记为意图。在获得弱标签信息后,添加一个辅助训练目标,迫使模型学习分解的关键词和意图表示。
关键词和意图分类损失定义如下:
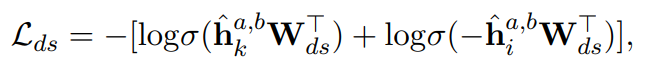
其中,hk,hi分别对应于关键词和意图的表示。上述公式中的目标是推动编码器学习关键词和意图的表示,使它们彼此远离,在不同的匹配级别对分解的句子内容进行建模。
自动关键词标注
论文用启发式方法生成远程监督标签,用于关键词和意图的识别。
- 首先从NLTK中提取潜在的关键词,其中包含名词、动词和形容词的词性标签。
- 然后,我们使用外部知识库来匹配这些潜在的关键词:英语语料库的维基百科实体图,Chinese Medical-SM的搜狗知识图谱。
- 最后,使用二进制IO格式来标记token是否属于关键词或意图。
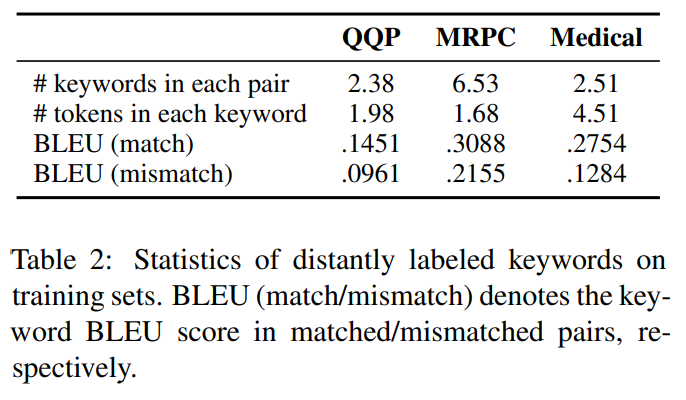
表2显示了三个基准测试的训练集上远程标注关键词的统计量。使用BLEU分数来衡量两个比较句子之间关键词的相关性,包括匹配对和不匹配对。匹配的句子对通常包含相关度较高的关键词。因此,通用模型可能只以匹配的关键词为条件而错误地输出高匹配分数,而不考虑上下文,因为模型倾向于学习数据中的统计偏差。
分而治之匹配策略
然而,远程监督中的辅助训练目标不能与原始文本匹配问题直接关联。为了促进关键词和意图对最终预测的真正贡献,引入了一种新的匹配策略,遵循分而治之的思想。具体地,将原匹配问题分解为两个简单的子问题:关键词匹配和意图匹配,并假设它们彼此独立。然后将子问题的解组合起来,得到原问题的解。
文本语义匹配的目标是学习y = ξ(Sa, Sb),其中y可以是二分类目标,也可以是多分类目标。假设每个子问题遵循相同类型的目标,由两个子问题P(yk, yi)的联合概率分布可以得到组合解Q(y)的概率分布:
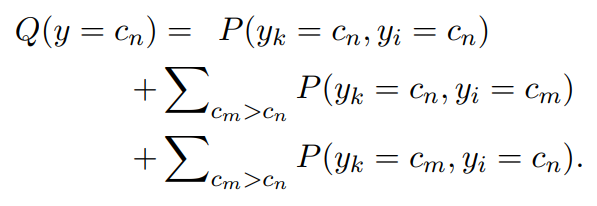
其中,cn、cm表示反映匹配程度的目标类别,cm > cn表示cm比cn具有更高的匹配分数。例如,在一个三分类场景中,y∈{2,1,0}分别表示精确匹配、部分匹配和不匹配,Q(y = 0)是至少一个子问题被推断为不匹配的概率。
分别比较关键词和意图,得到条件概率:
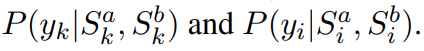
Sk和Si分别表示意图或关键词tokens被掩码的文本序列。那么,在子问题独立的假设下,yk和yi的条件联合分布为:
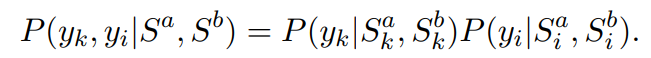
最后,可以结合子问题的解决方案,并使用公式5计算条件分布Q(y|Sa, Sb)。为了保证全局匹配分布(原问题)与子问题组合解的分布相似,我们使用双向KL散度损失来最小化P(y|Sa, Sb)与Q(y|Sa, Sb)之间的距离,如下所示:
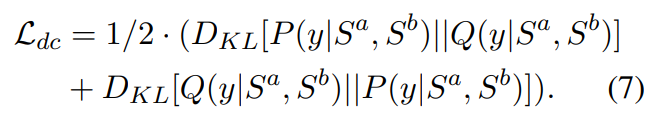
通过这种方式,期望全局匹配模型学习做出具有更好可解释性的最终预测,这取决于需要不同级别匹配粒度的分解关键词和意图。
训练和推理
在训练阶段,结合三个损失函数Lsm,Lds,Ldc来联合训练模型:

在推理时,直接根据原问题的条件概率推断出句子对的匹配类别:
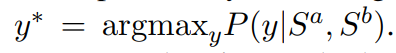
推理过程与PLM基线完全相同,而无需额外的计算。在这里,论文不从组合解Q(y|Sa, Sb)的概率推断匹配结果。由于推理时一般没有关键词和意图的标注信息,不能直接计算Q(y|Sa, Sb)。虽然使用外部语料库自动获取远程标注,但它可能会存在不完整和噪声的信号,给Q(y|Sa, Sb)近似带来偏差。因此,在训练阶段只使用远程标签作为全局匹配模型的辅助信息增强。然而,经过模型训练,P(y|Sa, Sb)与Q(y|Sa, Sb)高度一致。因此,通过更好地近似Q(y|Sa, Sb),一组高质量的关键字标签可能会带来额外的性能提升。
分而治之策略分析
模型在测试时无法获得标注的关键词,因此无法直接计算子问题Q(y)的组合解的概率。因此,公式7中的KL-divergence损失旨在最小化Q(y)与全局匹配概率P(y)之间的距离,旨在模拟推理时的分而治之过程。
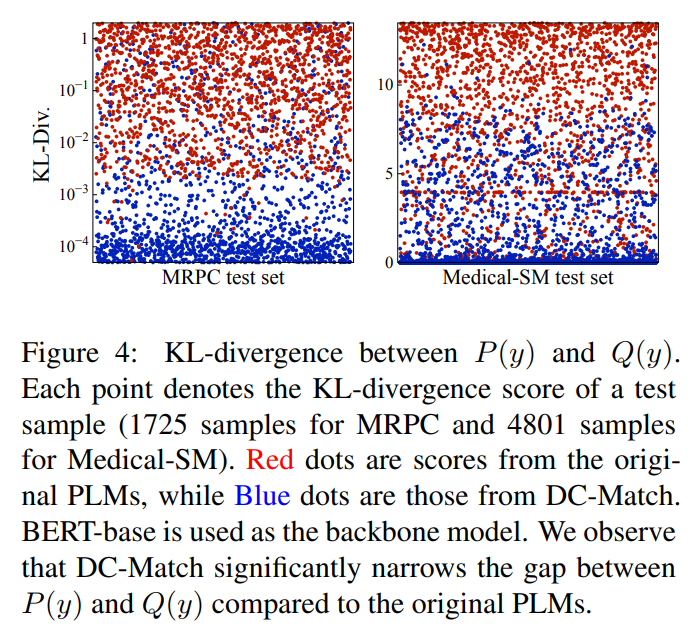
论文为每个测试样本计算P(y)和Q(y)之间的KL-divergence分数,并在图4中说明结果。红点表示来自原始PLMs的分数,蓝点是来自DC-Match的分数。可以观察到P(y)和Q(y)表现出更高的一致性(较低的KL-Div分数)与原始PLMs相比,这再次证明了所设计的分治训练目标的有效性,该目标缩小了P(y)和Q(y)之间的差距。
结论
设计了一种分而治之的文本语义匹配训练策略DC-Match。它将匹配问题分解为两个子问题:关键词匹配和意图匹配。该模型学习将关键词从需要不同级别匹配粒度的意图中分离出来。提出的DC-Match简单有效,可以很容易地与PLMs结合,且只需少量额外参数。在三个不同语言的文本匹配数据集上进行了实验。实验结果表明,该方法不仅可以获得稳定的性能提升,而且对语义不变的文本变换具有鲁棒性。