摘要
知识库问答(KBQA)的目的是在外部知识库的帮助下回答自然语言问题。其核心思想是找到问题背后的内部知识与知识库中已知三元组之间的联系。传统的KBQA任务piplines包含实体识别、实体链接、答案选择等步骤。在这种pipline方法中,任何过程中的错误都会不可避免地传播到最终的预测。为了解决这一问题,论文提出了一种基于预训练语言模型的语料库生成-检索方法(Corpus Generation – Retrieve Method,CGRM)。主要的创新之处在于新方法的设计。其中,知识增强T5 (kT5)模型旨在基于知识图谱三元组生成自然语言QA对,并通过检索合成数据集直接求解QA。该方法可以从PLM中提取更多的实体信息,提高精度,简化过程。我们在NLPCC-ICCPOL 2016 KBQA数据集上测试了我们的方法,结果表明该方法提高了KBQA的性能,并且与最先进的方法相比具有竞争力。
背景和挑战
问答系统是自然语言处理领域长期以来的研究热点。一个方向是将已有的知识库用于自然语言问题,称为知识库问答(Knowledge Base Question Answering, KBQA)。目前KBQA的主流方法是将当前问句的实体链接到KBQA实体中,利用句子中出现的关系归纳到知识图谱中得到最终答案。目前,KBQA任务主要通过一组分步处理的pipline来解决,包括实体识别、关系抽取、实体链接、答案选择,如图1所示。在应用上述pipline方法时,中途发生的任何错误都会影响到后续所有的pipline链接,从而在很大程度上降低整个KBQA系统的性能。
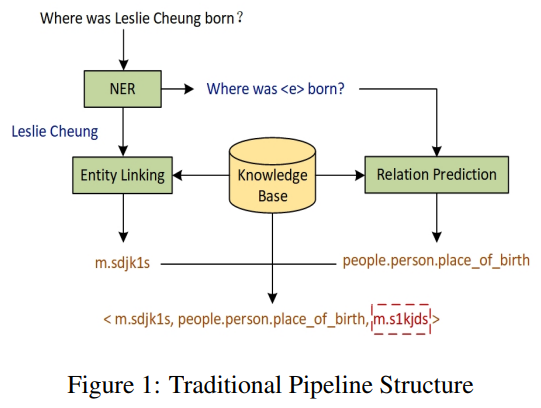
解决方案
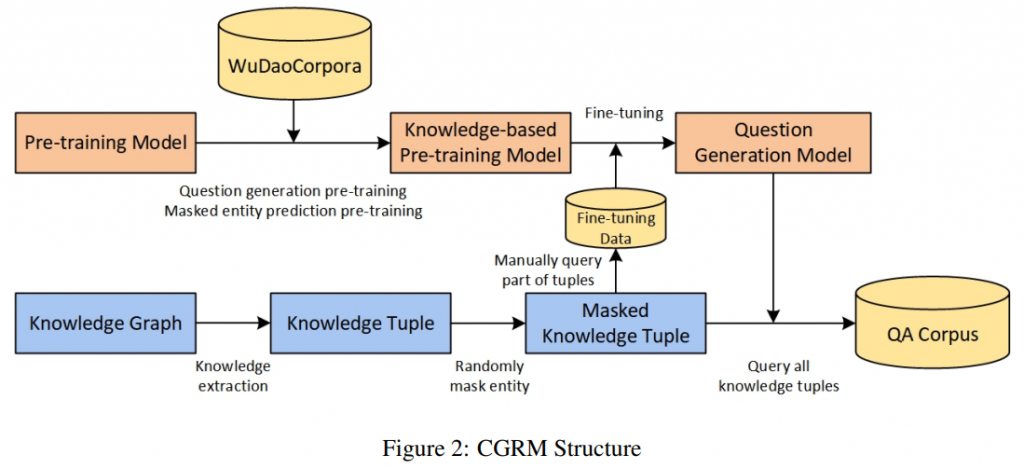
为了应对这一挑战,提出了一种语料库生成-检索方法(Corpus Generation-Retrieve Method, CGRM)。过程如图2所示。在该方法中,利用预训练好的模型对处理后的知识三元组进行查询,生成庞大的问答语料库。用户问题的最终答案可以通过检索语料库中生成的相似问题得到。
- 在mT5 模型的基础上,设计了两个新的预训练任务:知识掩码语言建模和基于段落的问题生成,以获得知识增强的T5 (kT5)模型。同时,用一个额外的稀有汉字列表扩展了模型的词汇列表。与mT5模型相比,kT5在单词知识和小样本学习方面得到了增强。此外,为了增强模型的语言生成能力,kT5将每个单词视为一个单元,可以有效缓解生成任务中的重复问题。
- 然后使用[MASK]符号替换知识图谱三元组中的任何实体,使该实体成为答案。将掩码后的三元组作为输入,借助kT5模型进行seq2seq微调,为这些三元组生成问题,并生成问题和相应的答案共同构成庞大的QA语料库。随后,使用微调后的模型生成详尽的问答对语料库。
- 最后,将KBQA任务转化为检索问题。通过计算问题相似度,可以在生成的问答数据集中检索用户问题的答案。
贡献
综上,提出了一种新的面向KBQA任务的方法,该方法可以从PLM中提取更多关于实体的信息,从而提高准确率,简化过程,并消除错误传导问题。通过实验证明了其在问答中的性能优势。在线部署KBQA系统时,只需在一轮中使用用户查询检索生成的数据集,从而大大简化了操作过程,提高了部署系统的效率。主要贡献总结如下:
- 针对KBQA任务提出了一种CGRM方法,提高了流水线精度和部署效率。此外,该方法不需要领域知识和手工特征或模型结构设计。
- 针对KBQA任务,本文提出了预训练知识增强的mT5 (kT5),它显示了巨大的少样本学习能力。这种少秀学习能力有利于各种领域的KBQA部署,而无需大量训练。
- 在此基础上,该文提出了一个面向问答研究的语料库。
方法
kT5
在论文中,使用mT5作为预训练模型骨干。为了使mT5模型能够从知识图谱中生成更好的自然语言问答对,通过增加两个额外的预训练任务和词汇表配置来改进mT5模型,以获得知识增强的T5模型(kT5)。
预训练任务
根据目标任务,定义了两个预训练任务,应用谷歌mT5的基本结构和初始权重,如图3所示。
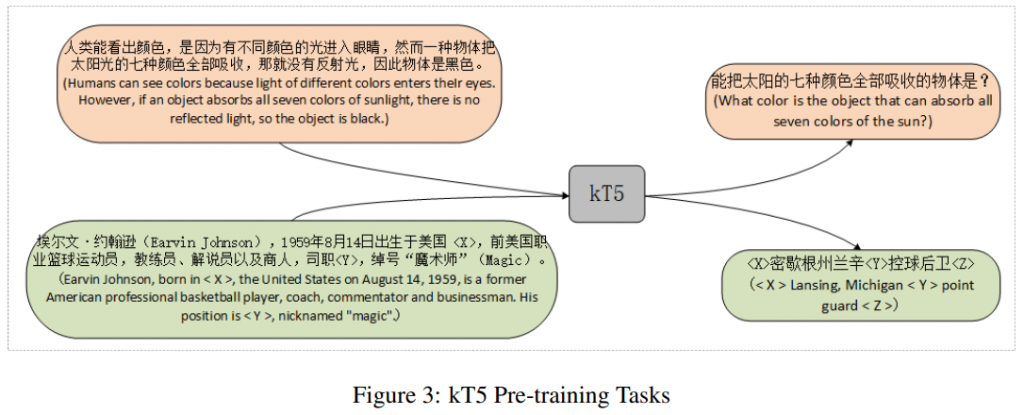
- 基于段落的问题生成。使用WebQA和SogouQA的文章和答案对训练模型,以提高其问题生成能力。
- 知识掩蔽语言建模。该任务类似于为T5模型设计的无监督预训练任务,T5是对输入文本中被屏蔽实体的预测。论文使用WuDaoCarpora中百科条目的摘要作为训练数据。本文对百科全书条目摘要中的链接实体进行掩码,而不是随机掩码句子中的单词,以增强训练好的kT5模型的单词知识。
词汇表配置
在mT5模型中,文本使用SentencePiece编码为WordPiece tokens。对于所有实验,mT5使用了25万个单词的词汇表。然而,原SensePiece算法在中文环境下分词性能较差,效果不佳,且该算法会强制将一些全角符号转换为半角符号。因此,作者使用pkuseg将文本编码为WordPiece标记。此外,kT5模型主要针对中文任务设计,并支持英语作为辅助语言。然而,mT5模型使用了大量其他语言的词汇表,导致嵌入层的参数过度占用。因此,作者对中文词汇进行补充,并删除非中文或非英文词汇,将总词汇量减少到5万个。
问题自动生成
使用NLPCC-ICCPOL 2016 KBQA任务提供的知识库进行实验。它是事实的集合,以(主语、谓语、宾语)的形式存储为三元组。为了更高效地查询,将知识图谱存储在neo4j数据库中。为了通过使用预训练模型从知识图谱中生成一个大型QA语料库,遵循图4所示的几个重要步骤。
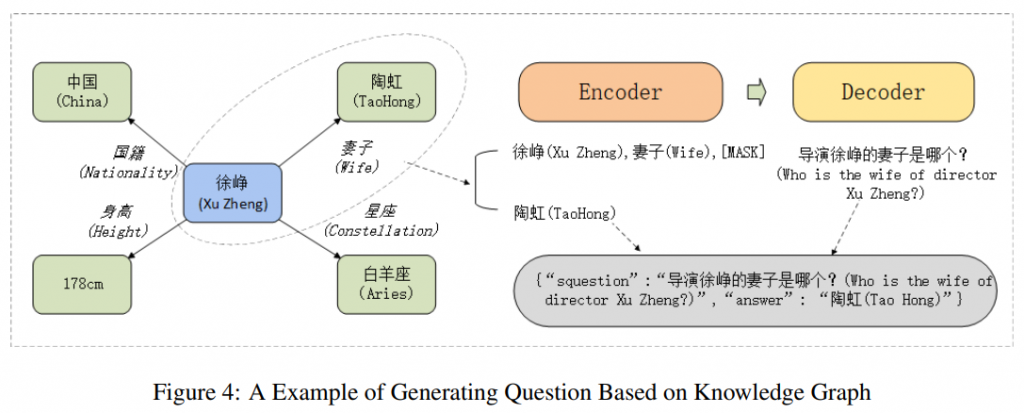
- 知识提取后的流程如图4右侧所示。使用
[MASK]作为特殊标记,对上述规则提取的知识三元组中的对象进行掩码。这些生成的问题和相应的知识元组共同构成kT5端到端微调的训练数据。具体来说,为了微调问题生成的模型,这些处理过的知识元组被用作kT5编码器的输入。生成的问题应该是解码器的输出。 - 接下来,如图4中间所示,微调后的模型查询处理后的完整知识元组集,这些生成的问题和掩码实体形成了一个大型的原始QA语料库。
- 最后,为了避免文本生成任务中偶尔出现的重复问题,使用启发式规则根据生成问题的质量对原始QA数据集进行过滤。在细节上,对每个生成的文本进行分割,并计算其中每个单词的比例。如果一个词在一个问题中的比例超过70%,相应的QA对将从数据集中删除。
检索
该文使用稀疏向量空间模型BM25结合BERT进行问句检索。之所以使用传统方法而不是更先进的方法,如密集嵌入模型,是因为作者想要排除检索算法的影响,从而证明所提出的CGRM系统的有效性。
召回算法
Best Match25 (BM25)是一种根据所提出的查询对信息检索系统中的文档进行评分的算法。
- 首先,解析查询词的语素,生成语素qi;
- 然后,针对每个检索结果D,计算每个语素qi与D的相关分数;
- 最后,将qi相对于D的相关分数加权求和,得到查询与D的相关分数。
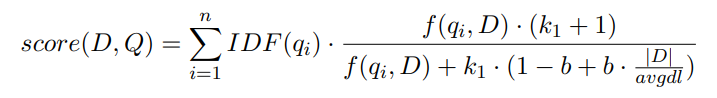
其中Q是文档集合,D是查询语句。IDF(qi)表示文档集合Q中单词qi的IDF值,f(qi, D)表示文档D中单词qi的TF值,k1为词频饱和度,用于调节饱和度变化速率。b是字段长度缩减,用于将文档长度缩减到所有文档的平均长度。它的值在0到1之间,1表示所有归约,而0表示不归约。|D|表示查询语句的长度,avgdl表示所有文本的平均长度。论文实验结果表明,当从BM25中检索到350个问题时,模型的性能最好。
排序算法
在对话系统中,BERT可以用来选择和排序候选答案。将查询和候选问题串联成一个序列,以[CLS]作为序列的开始,在查询和候选问题之间插入[SEP]作为分隔符,通过计算tmax在[CLS]处的位置来判断答案是否合理,并根据正例的概率分布进行排序,得到最终结果。
结论
目前的KBQA方法大多使用pipline来提取或表示问题中的语义信息,并尝试将这些特征与知识库进行匹配以得到最终的预测结果,这可能会在pipline中积累误差。此外,手工设计的特征表示或模型结构需要精心设计,难以对语义差异具有鲁棒性。
为解决这些问题,论文提出了一种直接的解决方案,利用预训练模型和知识图谱。通过使用预训练的kT5模型,基于从知识图谱中召回的三元组生成了一个大型的问答语料库,该语料库可以用于召回,但也可以用于问答研究。基于该语料库,只需根据问题相似度在该语料库中进行检索,就可以直接得到用户问题的最终答案。在NLPCC KBQA数据集上验证了该方法。实验结果表明,该方法的F1值达到85.77%,远远超过了其他算法的性能。此外,在KBQA系统在线运行时,只需一轮检索就可以回答用户提出的问题,具有较高的部署效率,可以降低服务器负载和成本。此外,作者证明了kT5的小样本学习能力,可以在不进行太多训练的情况下轻松进行各种域部署。