前言
论文:https://arxiv.org/pdf/2006.15509.pdf
代码:https://github.com/cliang1453/BOND
摘要
论文研究了远程监督下的开放域命名实体识别(NER)问题。远程监督虽然不需要大量的人工标注,但通过外部知识库产生高度不完整和噪声的远程标签。为应对这一挑战,论文提出一种新的计算框架——BOND,利用预训练语言模型(如BERT和RoBERTa)的力量来提高NER模型的预测性能。具体而言,提出了一种两阶段的训练算法:第一阶段,使用远程标签使预训练语言模型适应NER任务,可以显著提高召回率和准确率;在第二阶段,删除了远程标签,并提出了一种自我训练的方法,以进一步提高模型的性能。在5个基准数据集上的彻底实验表明,BOND比现有的远程监督NER方法具有优越性。
挑战
- 第一个挑战是不完全标注,这是由现有知识库的覆盖率有限造成的。这个问题导致许多实体不匹配,并产生许多假阳性标签,这可能会显著损害后续的NER模型训练。
- 第二个挑战是噪声标注。由于标注的模糊性,标注往往是有噪声的——同一个实体可以映射到知识库中的多种实体类型。例如,实体提到“利物浦”可以映射到知识库中的“利物浦城市”(类型:LOC)和“利物浦足球俱乐部”(类型:ORG)。现有方法采用基于类型流行度的标签归纳方法,可能会导致对流行类型的匹配偏差。因此,它会导致许多假阳性样本,并损害NER模型的性能。
通常在标签精度和覆盖率之间存在权衡:生成高质量的标签需要设置严格的匹配规则,这可能不会对所有标签都很好地泛化,从而降低覆盖率并引入假阴性标签。另一方面,随着标注覆盖率的提高,由于标注歧义性,标注错误的数量也在不断增加。综上所述,生成对目标语料库具有高覆盖率的高质量标签仍然是非常具有挑战性的。
方法
为了充分利用预训练语言模型的力量来应对这两个挑战,本文提出一个两阶段的训练框架。
- 在第一阶段,我们使用远程匹配的标签微调RoBERTa模型,从本质上迁移RoBERTa中的语义知识,这将提高从远程监督的预测质量。值得注意的是,论文采用提前停止的方法来防止模型过度拟合不完整的标注标签,并显著提高召回率。然后使用RoBERTa模型来预测所有数据的一组伪软标签。
- 在第二阶段,将远匹配的标签替换为伪软标签,并设计一个教师-学生(teacher-student)框架来进一步提高召回率。学生模型首先由第一阶段学习到的模型初始化,并使用伪软标签进行训练。然后,从上一次迭代的学生模型中更新教师模型,为下一次迭代生成一组新的伪标签,以继续训练学生模型。这种教师-学生框架的优点是它逐步提高了模型对数据的置信度。此外,根据学生模型的预测置信度选择样本,进一步提高软标记的质量。这样可以更好地利用知识库信息和语言模型,提高模型的拟合能力。
两阶段框架(BOND)
在BOND的第一阶段,将BERT模型适应远程监督命名实体识别任务。在第二阶段,使用一种自训练的方法提高模型对训练数据的拟合。模型框架如图:
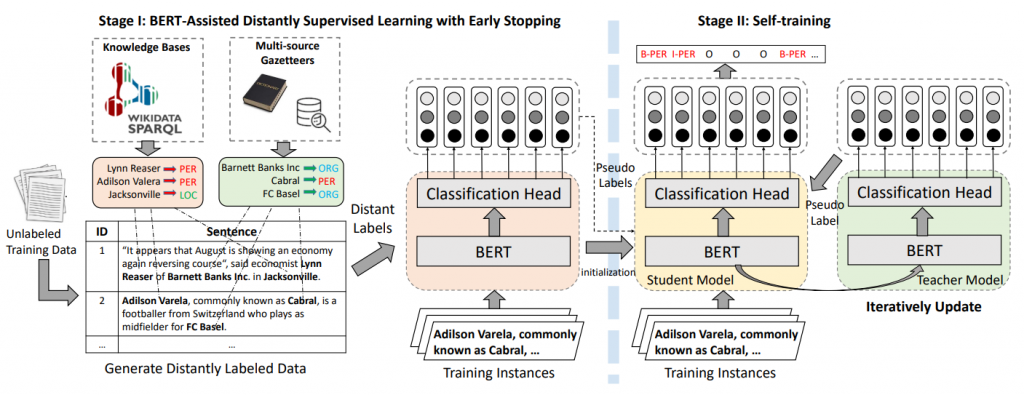
第一阶段
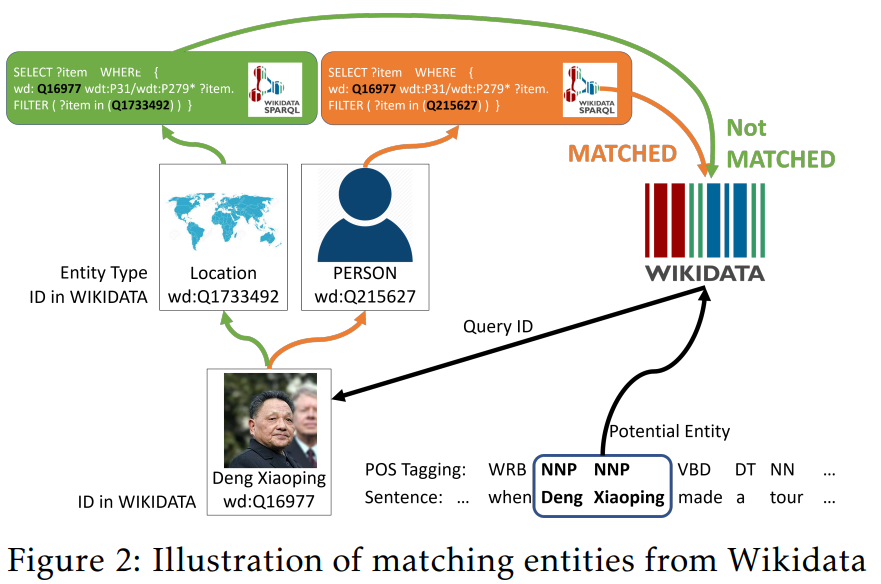
开放域NER任务生成远程标签。该标签生成方案包含两个步骤:首先通过词性标注和手工规则识别潜在实体;然后,使用SPARQL从Wikidata查询以识别这些实体的类型,如图2所示。接下来,从多个在线资源中收集词典,以匹配数据中的更多实体。
NER模型f(·;θ)通过最小化损失来学习
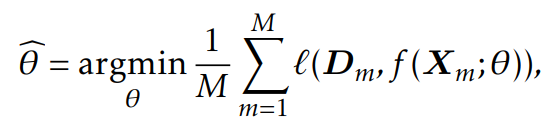
NER模型的架构f(·,·)是一个基于token的NER分类器,建立在预训练BERT之上,如图3所示。NER分类器从预训练的BERT层中获取token级输出嵌入,并给出对每个token类型的预测。预训练的BERT包含丰富的语义和语法知识,并产生高质量的输出嵌入。使用这样的嵌入作为初始化,可以使用随机梯度算法有效地使预训练BERT适应目标NER任务,例如ADAM。自适应过程更新整个模型,包括NER分类层和预训练BERT层。
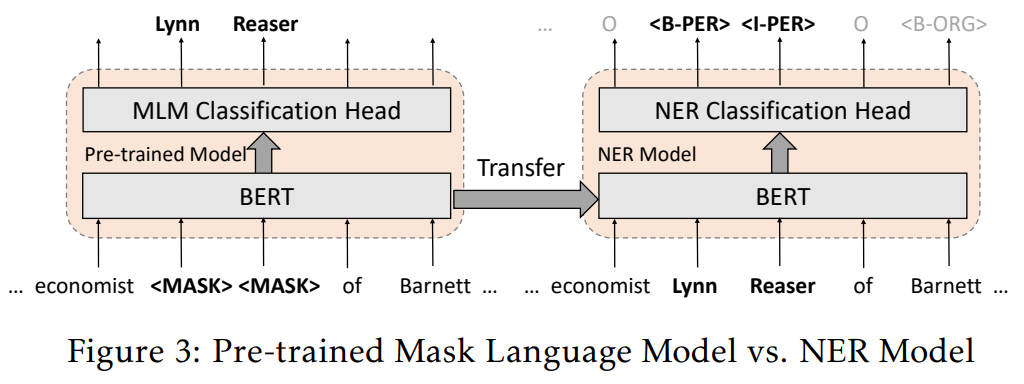
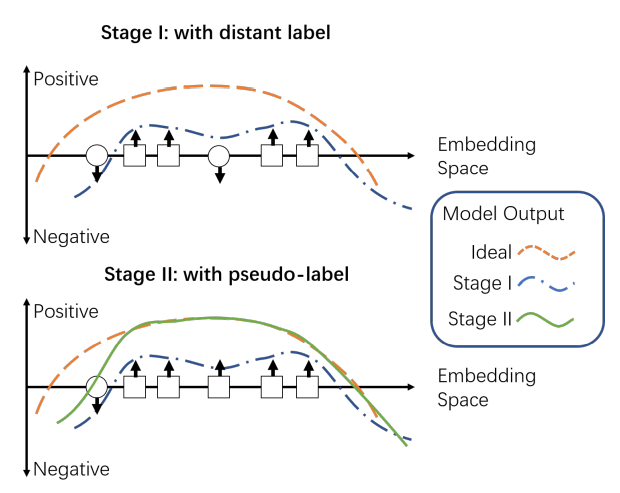
图4说明了预训练BERT嵌入如何帮助模型适应远程监督NER任务。BERT是通过掩码语言模型(MLM)任务进行预训练的,能够利用上下文信息预测缺失的单词。这样的MLM任务与NER任务有很多相似之处。它们都是token-wise分类问题,并且严重依赖上下文信息(见图3)。这自然会使预训练BERT的语义知识迁移到NER任务中。因此,与仅使用远程标注数据从头训练的模型相比,由此产生的模型可以更好地预测实体类型。
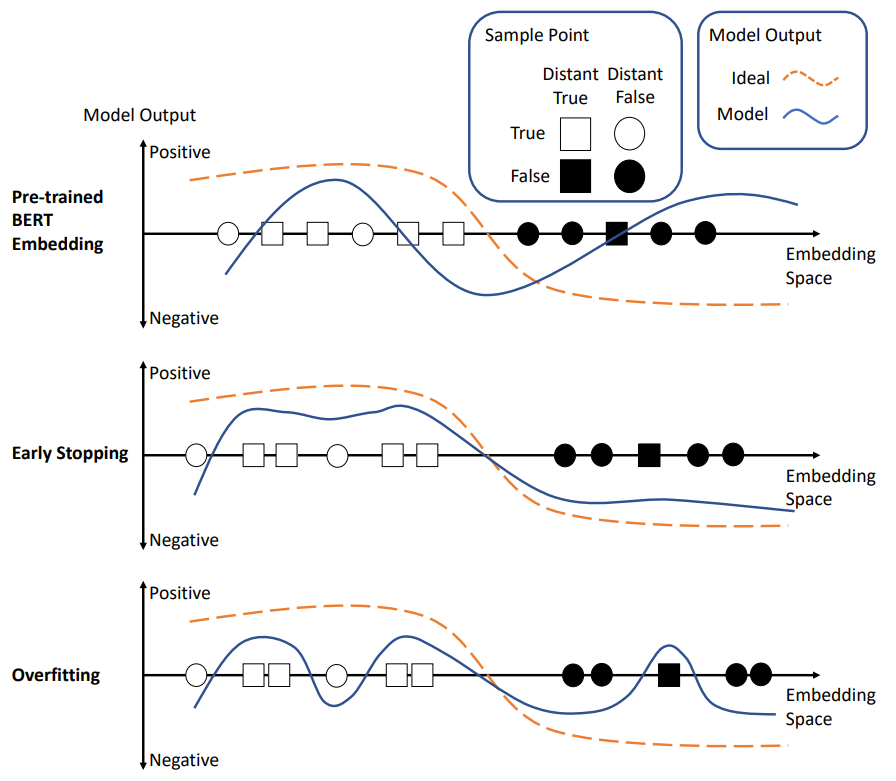
Early Stopping。我们在适应过程中使用的一个重要策略是早停法。由于模型容量大,且监督(远程标签)有限且有噪声,NER模型在没有任何干预的情况下,会对远程标签的噪声进行过拟合,从而忘记预先训练的BERT的知识。早停法本质上是一种强正则化,以防止这种过拟合,并提高对不可见数据的泛化能力。
第一阶段算法过程

第一阶段解决了远程监督命名实体识别任务中的两个主要挑战:噪声标注和不完整标注。通过将预训练BERT中的语义知识迁移到NER模型中,抑制噪声,提高预测精度。此外,早期停止可以防止模型过拟合不完整的标注标签,进一步提高召回率。
第二阶段(自训练)
首先描述了一个教师-学生的自训练框架来提高模型的拟合能力,然后提出使用高置信度软标签来进一步提高自训练能力。
教师-学生框架
使用第一阶段的参数初始化教师和学生模型
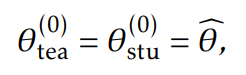
另一种选择为,使用BERT初始化学生模型,使用第一阶段训练的模型初始化教师模型
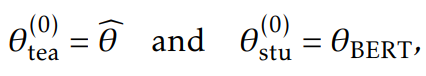
在第t次迭代时,教师模型通过下面公式生成伪标签
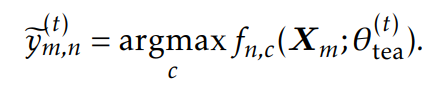
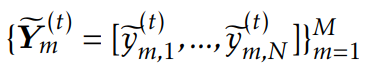
然后学生模型拟合这些伪标签。具体来说,给定教师模型
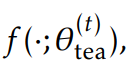
通过求解下面公式来学习学生模型
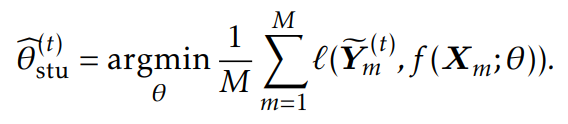
然后,使用ADAM优化提早停止的公式5。在第t次迭代结束时,更新教师模型和学生模型:
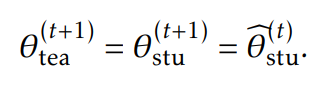
第二阶段算法过程

请注意,论文丢弃了(t-1)次迭代的所有伪标签,只使用教师模型在第t次迭代时生成的伪标签来训练学生模型。结合早停法,这种自训练方法可以提高模型拟合,减少伪标签的噪声,如图5所示。通过对伪标签的逐步细化,学生模型可以逐步利用伪标签中的知识,避免过拟合。
重新加权高置信度软标签
由公式4生成的硬伪标签只保留每个token的置信度最高的类。为了避免丢失过多其他类别的信息,论文建议使用置信度重加权的软标签。对于第m个句子中的第n个词项,C类的输出概率为:
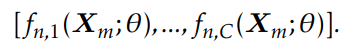
在第t次迭代时,教师模型生成软伪标签:
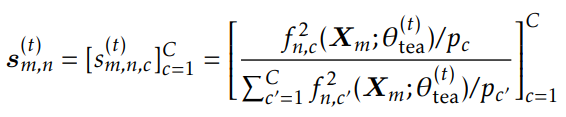
其中
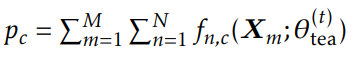
公式6中这样的步骤本质上有利于置信度较高的类。然后通过最小化来优化学生模型:
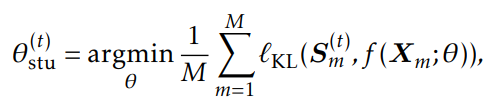
基于KL散度的损失:
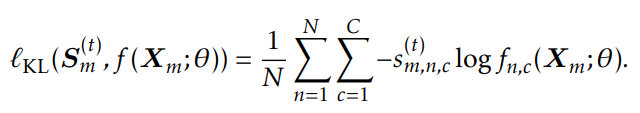
高置信度的选择
为了进一步解决数据中的不确定性,论文建议基于预测置信度选择tokens。高置信度选择本质上强制学生模型更好地拟合具有高置信度的tokens,因此能够提高模型对低置信度tokens的鲁棒性。