论文:https://aclanthology.org/2020.acl-main.412.pdf
论文概述
这篇文章结合知识补全的思想来改善知识库问答。通过自然语言理解这个问句并从知识库中寻找正确答案实体。多跳的问答则需要对关系路径进行推理。由于知识库不充分原因,现有的工作引入额外的文本弥补知识库稀疏问题。另外也有工作是通过目标实体从知识库中抽取多跳范围内的子图,在该子图内进行答案的检索。作者认为这是一种启发式的划定答案所在的领域。
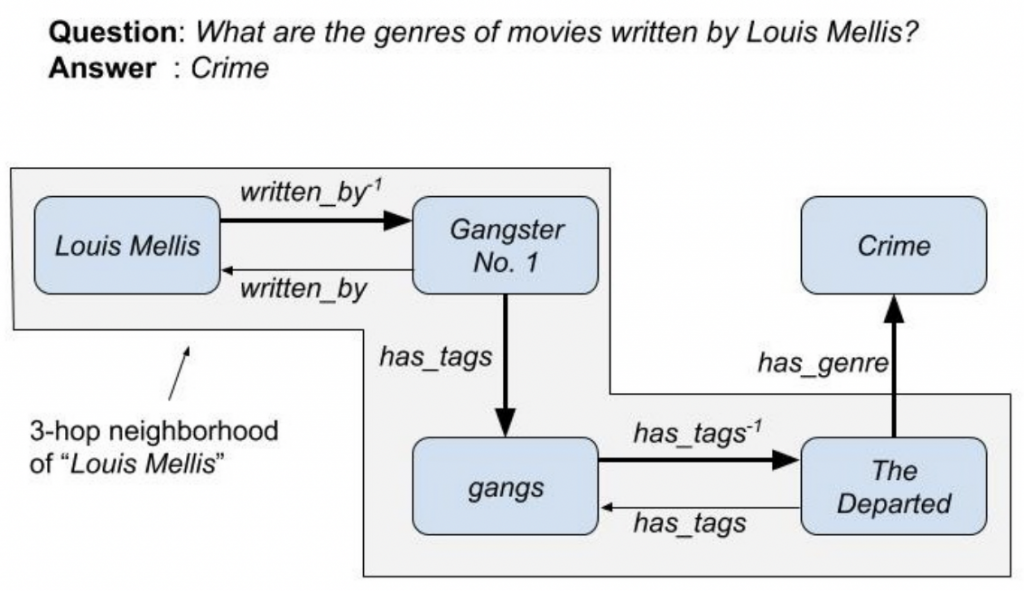
稀疏和不完整 KG 中多跳 QA over Knowledge Graphs (KGQA) 的挑战:当寻找对应的答案时,由于知识库不充分,“Louis Mellis”与答案“Crime”没有直接的边相连,则需要经过较长的路径推理。而启发式的设定跳数为3时(灰色区域),使得答案不在这个领域内,促使无法寻找到答案。
(2)不需要启发式地设定具体的领域范围;
整体架构
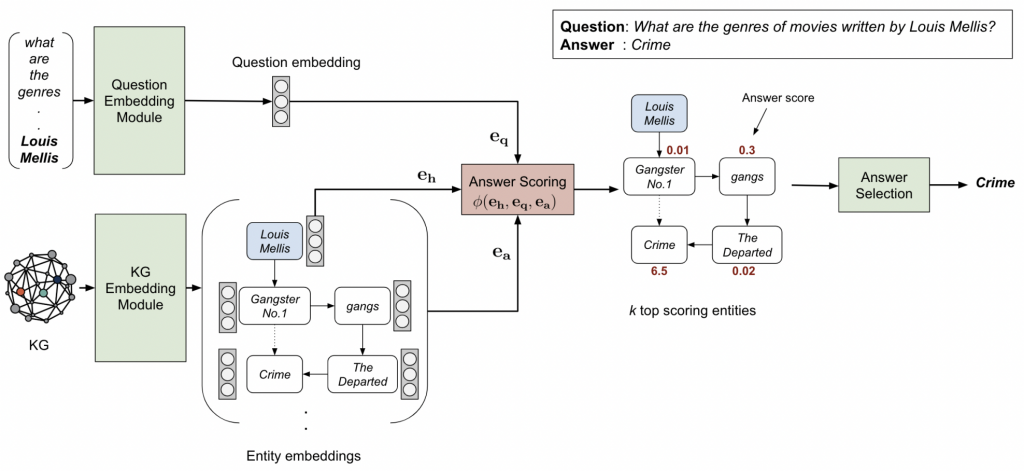
KG Embedding Module
作者使用ComplEx算法对整个知识库中的实体和边嵌入到固定大小的向量,作者之所以选择ComplEx算法,是因为该算法采用的是张量分解法,更能够捕捉更全面的特征。但在具体实验中,只获取实部的参数。
Question Embedding Module
对于问句 q, 作者使用 RoBERTa 预训练语言模型获得768维度的向量,并通过4层全连接层(激活函数为ReLU)映射到与知识表示相同维度的空间。在微调过程中,作者将问句替换到得分函数中的关系,这是一个比较巧妙的创新点,其借助ComplEx(或者说是知识表示学习的方法)的得分函数 ϕ 和排序损失函数训练的机制,促使目标实体 h和答案 t 之间的语义关系是问句q在复数空间中的表示。因为在有的知识库比较大,候选关系非常多,因此作者使用标签平滑方法。
Answer Selection Module
这一部分是核心,在已知知识图谱表征、每个三元组的得分以及问句的表征后,需要对候选答案进行筛选。对于知识库不大的可以按照上述的方法计算,但对于知识库较大的,则需要对候选的答案集合进行缩减(pruning),作者借鉴了PullNet算法,提出一种简单的缩减方法(Relation Matching)。