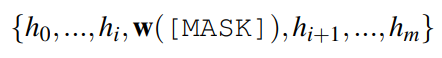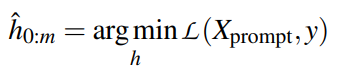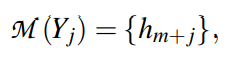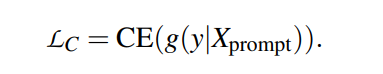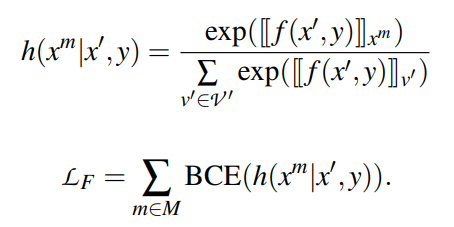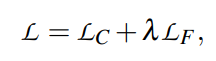前言
论文:https://arxiv.org/pdf/2001.07676.pdf%EF%BC%89
代码:https://github.com/timoschick/pet
摘要
一些NLP任务通过使用预先训练好的带有“任务描述”的语言模型,可以以完全无监督的方式解决。虽然这种方法的性能不如监督方法,但本篇工作中表明,这两种思想可以结合起来:作者引入了Pattern-Exploiting Training(PET),一种半监督的训练过程,它将输入示例重新定义为完形句式短语,以帮助语言模型理解给定的任务。然后使用这些短语为大量无标签的样本分配软标签。最后,对得到的训练集进行标准监督训练。对于一些任务和语言,PET在低资源环境下的表现远远优于监督训练和强半监督方法。
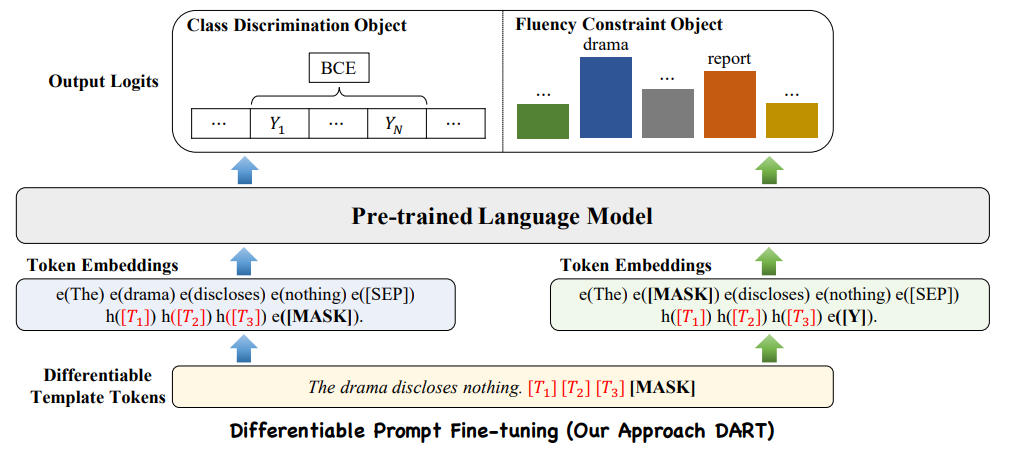
模型架构
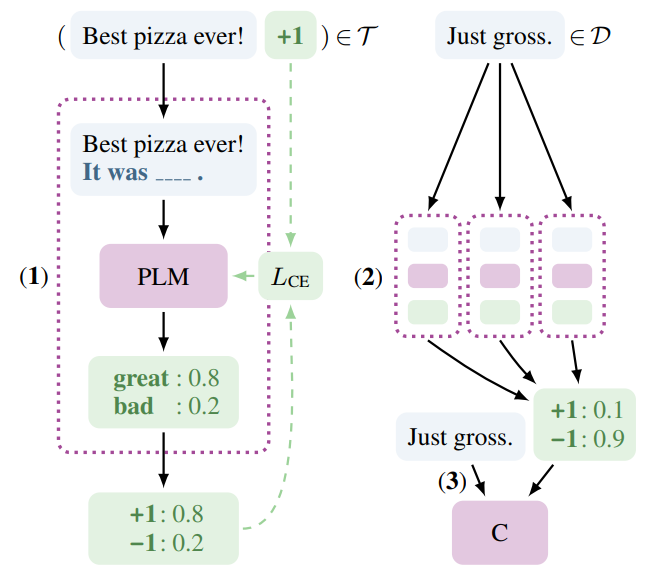
PET的工作过程分为三个步骤:
首先,针对每个模式,在小训练集T上对单独的PLM进行微调。
然后,使用所有模型的集合对一个大型的无标签数据集D进行软标签标注。
最后,在软标记数据集上训练标准分类器。
作者还设计了iPET,这是PET的迭代变体,该过程随着训练集规模的增加而重复。
Pattern-Exploiting Training
参数概况
M为预训练语言模型,词表为V,mask token包含在V中,任务A的标签集合L,输入序列x包含k个短语或句子。
定义一个模型函数(pattern)P,将x作为输入,输出包含一个mask token的短语或句子P(x),输出可以看作是一个完形填空。
定义一个映射函数(verbalizer)v,L—>V将每个标签映射到M的词汇表中的一个单词。
将(P, v)称为pattern-verbalizer pair(PVP)。
PVP Training and Inference
给定某个输入x,我们定义标签l∈L的分数为:
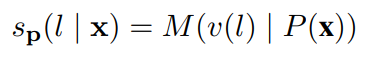
并使用softmax获得标签上的概率分布:
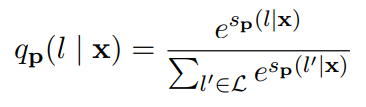
使用交叉熵作为微调的损失。
Auxiliary Language Modeling
只使用少量样本进行训练,可能发生灾难性遗忘。对于基于PVP的PLM微调,核心仍然是一个语言模型,我们通过使用语言建模作为辅助任务来解决这个问题。LCE表示交叉熵损失,LMLM表示语言建模损失,计算最终损失为:
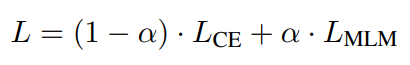
LMLM通常比LCE大得多,令α = 10−4
Combining PVPs
该方法面临的一个关键挑战是,在缺乏大型验证集的情况下,很难确定哪个PVPs表现良好。为了解决这个问题,使用了类似于知识蒸馏的策略。定义一个PVPs的集合P,直观地理解给定任务A的意义,按如下方法使用这些PVPs:
- 为每个p∈P微调一个单独的语言模型Mp
- 使用经过优化的模型的集合M = {Mp | p∈P}来标注集合D(未标注数据集合)。将每个样本x∈D的非归一化类分数合并为:
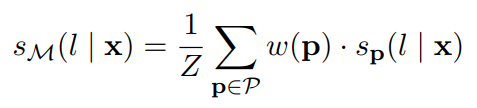
使用softmax将上述分数转换为概率分布q。使用T = 2得到适当的软分布。所有(x, q)对收集在一个(软标记的)训练集TC中。
- 在TC上,使用PLM微调得到模型C。经过优化的模型C作为对A的分类器。
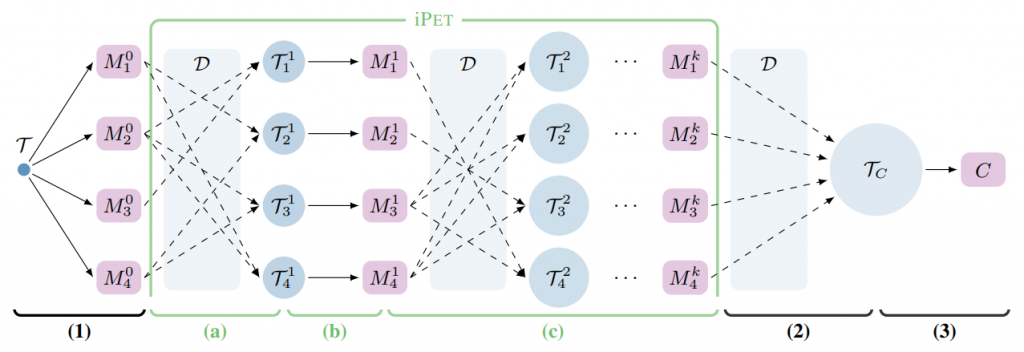
Iterative PET (iPET)
将所有单个模型的知识蒸馏到单个分类器中——意味着它们不能相互学习。由于有些模式的性能可能比其他模式差得多,因此最终模型的训练集TC可能包含许多标签错误的示例。为了弥补这个缺点,设计了iPET,它是PET的迭代变体。iPET的核心思想是在不断增大的数据集上训练几代模型。过程如图2所示。
- 对于每个模型,其他模型的一个随机子集通过标注D中的样本生成一个新的训练集。
- 使用更大的、特定于模型的数据集训练一组新的PET模型。
- 前两个步骤重复k次,每次都将生成的训练集的大小增加d倍。
经过训练k代PET模型,我们使用Mk创建TC和训练模型C在基本的PET。
结论
为预训练的语言模型提供任务描述可以与标准的监督训练相结合。PET方法包括定义成对的完形填空问题模式(patterns)和语言表达器(verbalizers),这有助于利用预训练的语言模型中包含的知识来完成下游任务。对所有模式-语言化器对的模型进行微调,并使用它们创建大型的带注释的数据集,标准分类器可以在这些数据集上进行训练。当初始训练数据量有限时,PET比标准监督训练和强半监督方法有很大的改进。