前言
论文:https://arxiv.org/pdf/2109.06270.pdf
代码:https://github.com/google-research/google-research/tree/master/STraTA
STraTA,Self-Training with Task Augmentation,基于任务增强的自训练
亮点
- STraTA使用任务增强技术,首先训练一个生成模型,然后使用给定目标任务的无标签文本合成大量域内训练数据,用于辅助任务微调,得到辅助任务模型。
- STraTA自训练算法使用标记和伪标记的样本迭代学习更好的模型。在每次迭代中,利用teacher-student方法,从任务扩展产生的辅助任务模型开始,并在广泛分布的伪标记数据上进行训练。
模型
模型架构
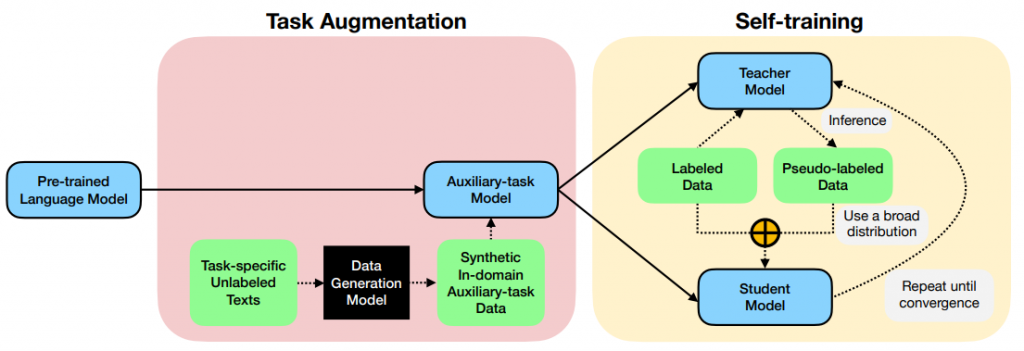
模型主要分为两个部分,一个是Task augmentation,生成Auxiliary-task Model;另一个是Self-training,利用teacher-student模式迭代训练。
任务描述
假设给定任务T,包括带标签的数据集L和无标签的数据集U,无标签的数据集U可以通过L人工制造,或者可以来自目标域或相关数据集/域的未标记文本。
任务增强(Task augmentation)
任务增强模块使用自然语言推理(NLI)作为辅助(中间)训练任务,以提高下游性能。
任务增强建立在最近的关于中间任务训练的NLP研究的基础上,其中预先训练的语言模型(如BERT)在目标任务之前对辅助任务进行微调。
论文关于中间微调的工作,使用的辅助数据集是一个固定目标任务无关的数据集,如MNLI或SQuAD。这种选择的一个明显的限制是辅助任务和目标任务之间的域不匹配,使用任务增强方法解决这一问题。对于给辅助任务A,利用无标签数据U结合微调的预训练生成语言模型合成大量的目标任务T域内的数据,来提高目标任务T的性能。
Generating synthetic NLI data
使用预训练的T5模型在带标签的句子对上做微调。训练样本将(sentA, sentB)→label 转化为(label, sentA)→sentB,获得微调的样本。将目标任务的数据集的数据经过微调的T5数据生成器生成增强样本。在推理时,向模型输入一个NLI标签label 和一个来自目标域的未标注的句子xj,以生成一些输出句子xk : (label,xj)→xk 。然后通过创建(xj, xk)→label 这样的样本来形成用于中间任务(Synthetic In-domain Auxiliary-task Data)微调的数据。
自训练(Self-training)
任务增强使用未标注的文本为中间辅助任务生成合成数据,而自训练是一种补充方法,它通过使用伪标记示例直接在目标任务上进行训练来改进模型。

Starting with a strong base model
自训练算法的一个重要组成部分是基础模型f0。成功的自训练通常需要一个良好的基础模型,它可以在未标注的样本上提供很大比例的“正确”预测或伪标记;否则,错误会在后期的自训练中传播或放大。在每次自训练迭代中,总是从相同的基础模型f0开始,该模型使用来自预训练/中间微调阶段(例如,任务增强中的辅助任务训练阶段),然后使用标注数据和伪标注数据对模型进行微调。
Self-training on a broad distribution of pseudolabeled data
通过在每次自训练迭代中向原始标记数据集L中添加整个U伪标记示例集,鼓励从伪标记数据的“自然”广泛分布中学习在每次迭代t >1时,我们也用ft重新注释原始未标记数据池U中的所有示例,因为我们预期ft优于ft−1。