HAO Unity系统架构
基于图的异构数据集成系统HAO Unity,HAO Unity系统整体框架如下图所示,主要组件包括:物理统一组件、语义统一组件、数据探索组件。物理统一组件负责通过属性图交换不同格式的数据。语义统一组件则从两方面来统一属性图中的异构数据:schema和instance。数据探索组件提供一个查询元数据、实体和关系信息的接口,方面用户了解集成后的数据,并进一步构建下游应用。
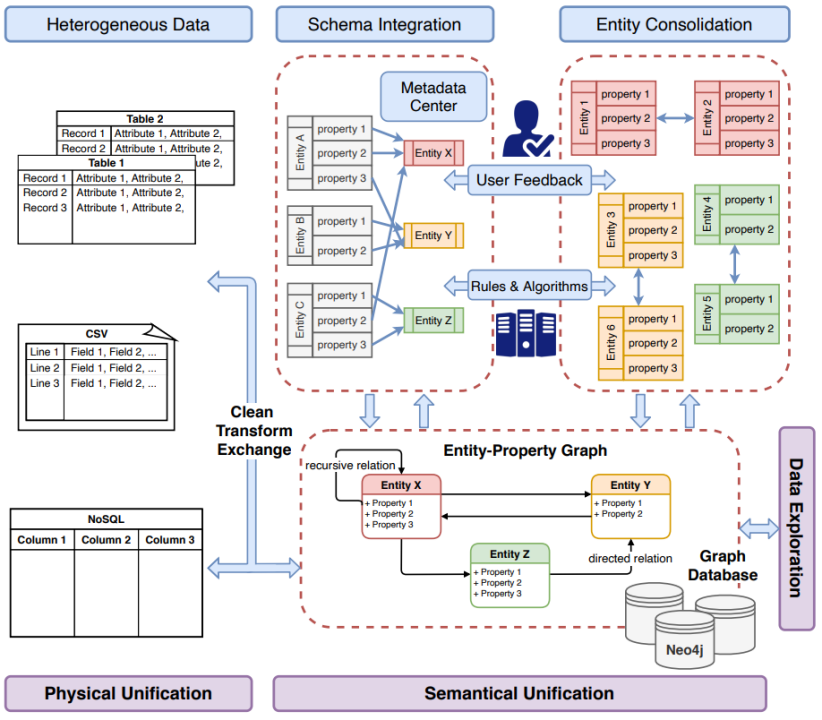
基于图的异构数据集成系统HAO Unity,HAO Unity系统整体框架如下图所示,主要组件包括:物理统一组件、语义统一组件、数据探索组件。物理统一组件负责通过属性图交换不同格式的数据。语义统一组件则从两方面来统一属性图中的异构数据:schema和instance。数据探索组件提供一个查询元数据、实体和关系信息的接口,方面用户了解集成后的数据,并进一步构建下游应用。
论文:https://arxiv.org/pdf/2109.08678.pdf
排名器是基于BERT双编码器(以输入问题-候选对作为输入)经过训练,以最大限度地提高基本事实逻辑形式的分数,同时最大限度地减少不正确候选者的分数。
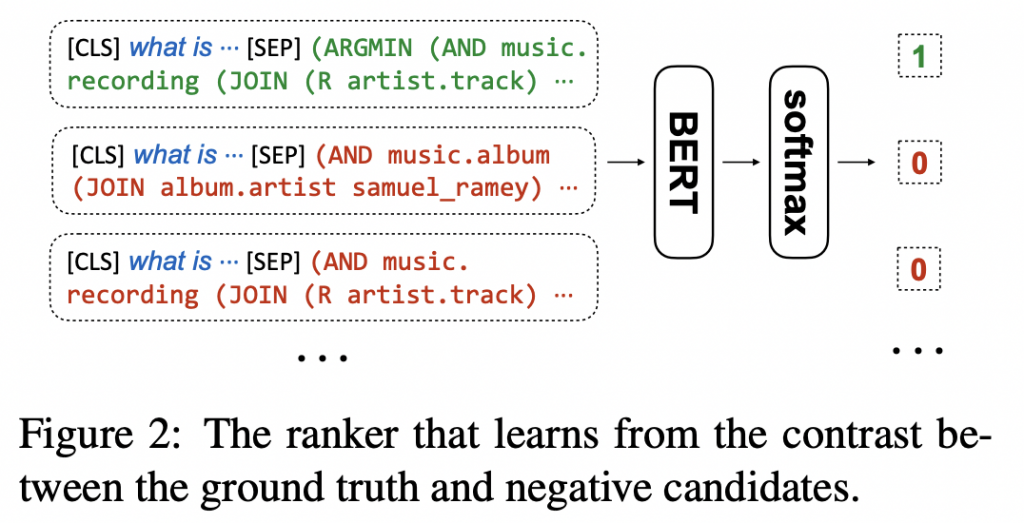
扩展了提出的逻辑形式排序器,保持架构和逻辑相同,用于实体消歧任务,并展示其作为第二阶段实体排序器的有效性。
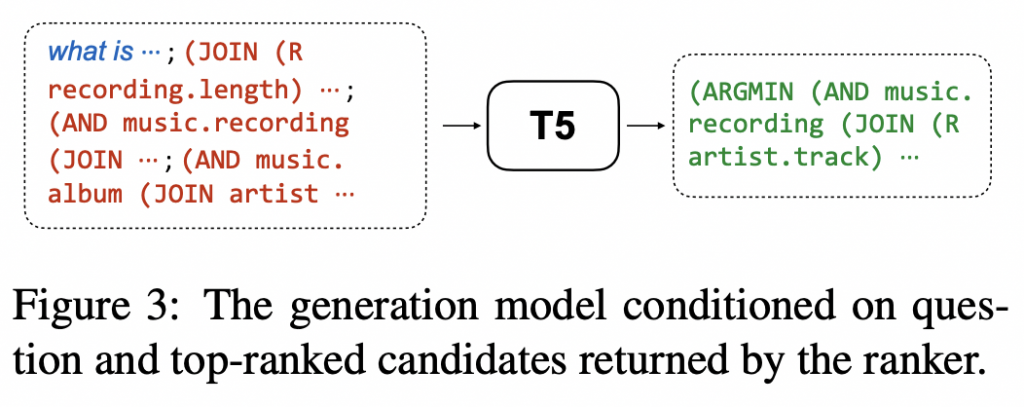
有了候选的排名列表,引入了一个生成模型来组成以问题为条件的最终逻辑形式和我们的排名器返回的前 k 个逻辑形式。 生成器是从 Raffel 等人实例化的基于转换器的 seq-to-seq 模型,因为它在生成相关任务中表现出强大的性能。 如图所示,通过连接问题和由分号分隔的排名器返回的前 k 个候选者(即 [x; ct1; …; ctk])来构建输入。
GRAILQA 是第一个评估零样本泛化的数据集。 具体来说,GRAILQA 总共包含 64,331 个问题,并仔细拆分数据,以评估 KBQA 任务中的三个泛化级别,包括 i.i.d. 设置、构图设置(泛化到看不见的构图)和零镜头设置(泛化到看不见的 KB 模式)。 我们在图中展示了组合泛化( compositional generalization )和零样本泛化( zero-shot generalization)的示例。测试集中每个设置的分数分别为 25%、25% 和 50%。 除了泛化挑战之外,GRAILQA 还存在额外的困难,包括大量涉及的实体/关系、逻辑形式的复杂组合性(最多 4 跳)以及问题中提到的实体的噪声。
论文:https://arxiv.org/pdf/2108.06688.pdf
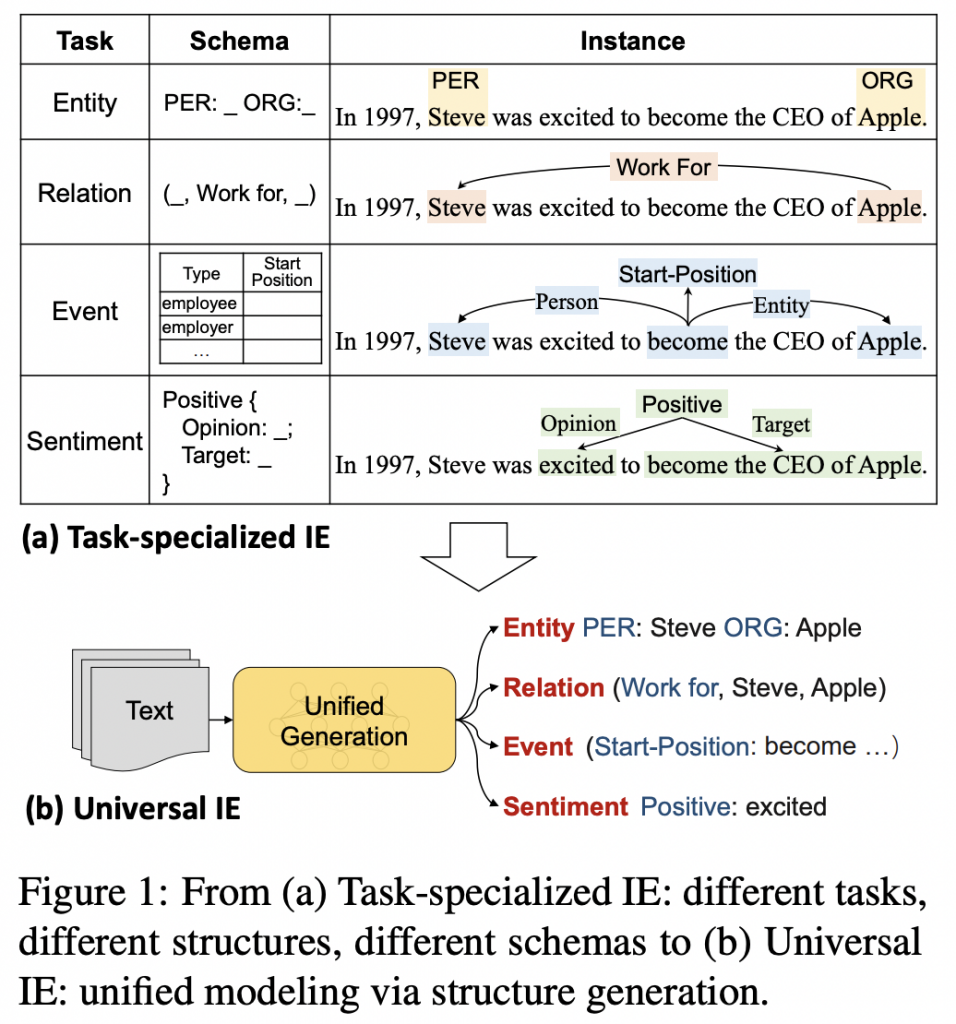
这篇论文是复杂KBQA方面的一篇综述。介绍了复杂 KBQA 的两大主流方法,即基于语义解析( semantic parsing-based, SP-based)的方法和基于信息检索(information retrieval-based, IR-based)的方法。从这两个类别的角度回顾了先进的方法并解释了对典型挑战的解决方案。
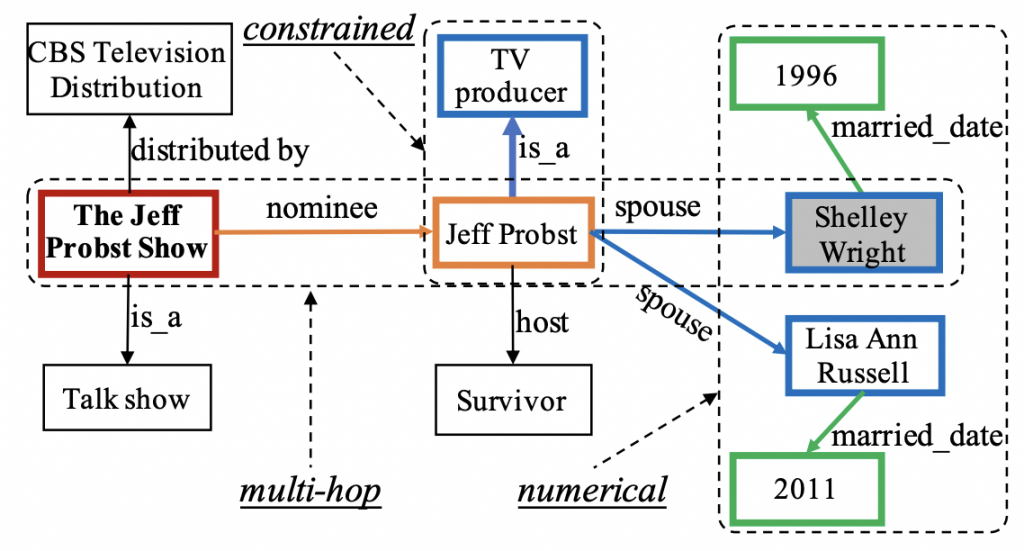
Who is the first wife of TV producer that was nominated for The Jeff Probst Show?
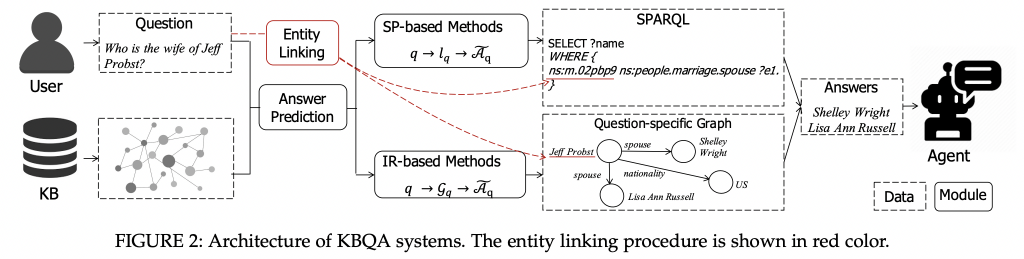
直接将传统知识图谱问答模型运用到复杂问题上,不管是基于语义解析的方法还是信息检索的方法都将遇到新的挑战:
论文:https://aclanthology.org/2020.acl-main.412.pdf
这篇文章结合知识补全的思想来改善知识库问答。通过自然语言理解这个问句并从知识库中寻找正确答案实体。多跳的问答则需要对关系路径进行推理。由于知识库不充分原因,现有的工作引入额外的文本弥补知识库稀疏问题。另外也有工作是通过目标实体从知识库中抽取多跳范围内的子图,在该子图内进行答案的检索。作者认为这是一种启发式的划定答案所在的领域。
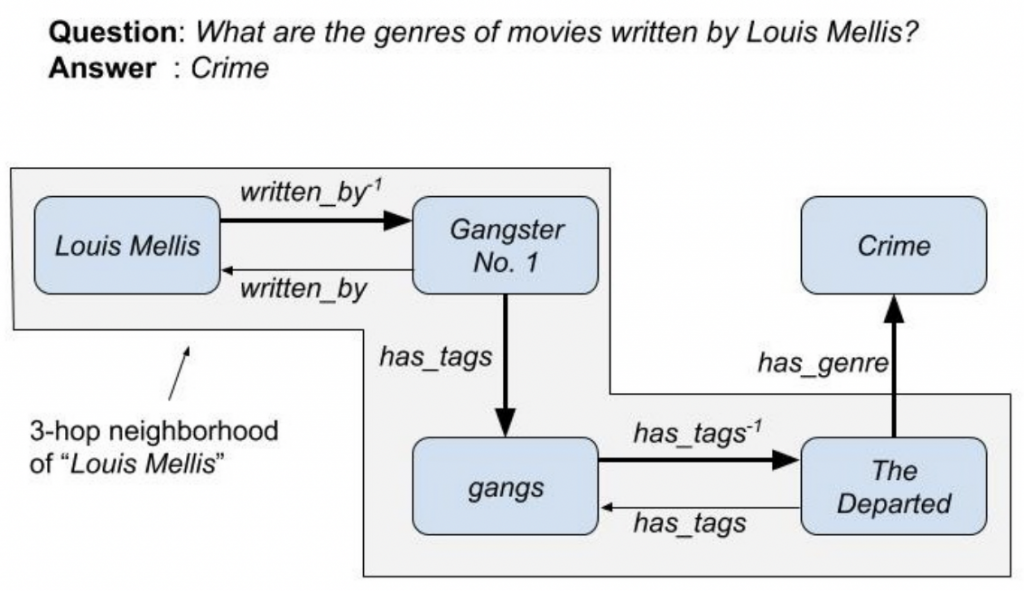
稀疏和不完整 KG 中多跳 QA over Knowledge Graphs (KGQA) 的挑战:当寻找对应的答案时,由于知识库不充分,“Louis Mellis”与答案“Crime”没有直接的边相连,则需要经过较长的路径推理。而启发式的设定跳数为3时(灰色区域),使得答案不在这个领域内,促使无法寻找到答案。
(2)不需要启发式地设定具体的领域范围;
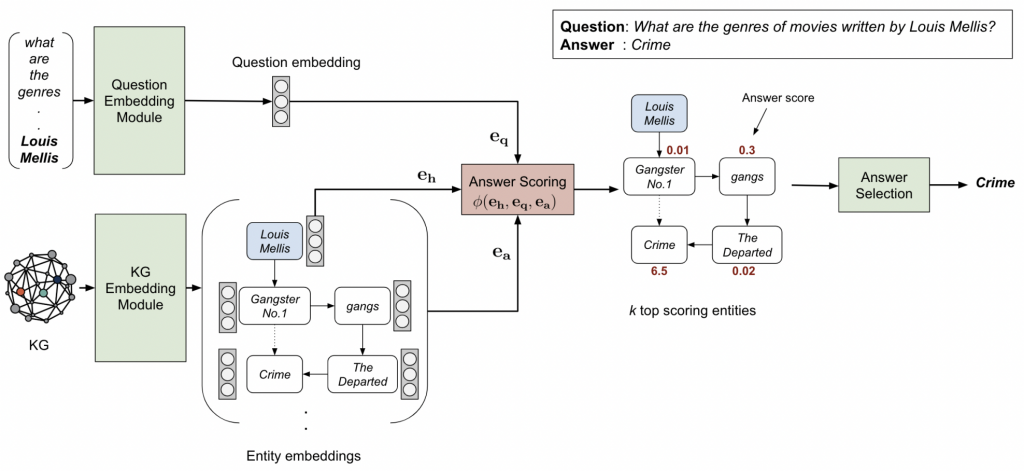
作者使用ComplEx算法对整个知识库中的实体和边嵌入到固定大小的向量,作者之所以选择ComplEx算法,是因为该算法采用的是张量分解法,更能够捕捉更全面的特征。但在具体实验中,只获取实部的参数。
对于问句 q, 作者使用 RoBERTa 预训练语言模型获得768维度的向量,并通过4层全连接层(激活函数为ReLU)映射到与知识表示相同维度的空间。在微调过程中,作者将问句替换到得分函数中的关系,这是一个比较巧妙的创新点,其借助ComplEx(或者说是知识表示学习的方法)的得分函数 ϕ 和排序损失函数训练的机制,促使目标实体 h和答案 t 之间的语义关系是问句q在复数空间中的表示。因为在有的知识库比较大,候选关系非常多,因此作者使用标签平滑方法。
这一部分是核心,在已知知识图谱表征、每个三元组的得分以及问句的表征后,需要对候选答案进行筛选。对于知识库不大的可以按照上述的方法计算,但对于知识库较大的,则需要对候选的答案集合进行缩减(pruning),作者借鉴了PullNet算法,提出一种简单的缩减方法(Relation Matching)。
论文:https://arxiv.org/pdf/2203.14655v2.pdf
代码:https://github.com/symanto-research/few-shot-learning-label-tuning
在训练数据很少或没有训练数据的情况下构建文本分类器的问题,通常称为零样本和小样本文本分类。近年来,一种基于神经文本蕴涵模型的方法已被发现在不同的任务范围内提供强大的结果。在这项工作中表明,通过适当的预训练,嵌入文本和标签的Siamese网络提供了一个有竞争力的替代方案。这些模型大大降低推理成本:标签数量恒定,而不是线性。此外,还引入了标签调优,是一种简单且计算效率高的方法,它允许通过仅更改标签嵌入来在少量设置中适应模型。虽然提供比模型微调更低的性能,但这种方法具有体系结构上的优势,即单个编码器可以由多个不同的任务共享。
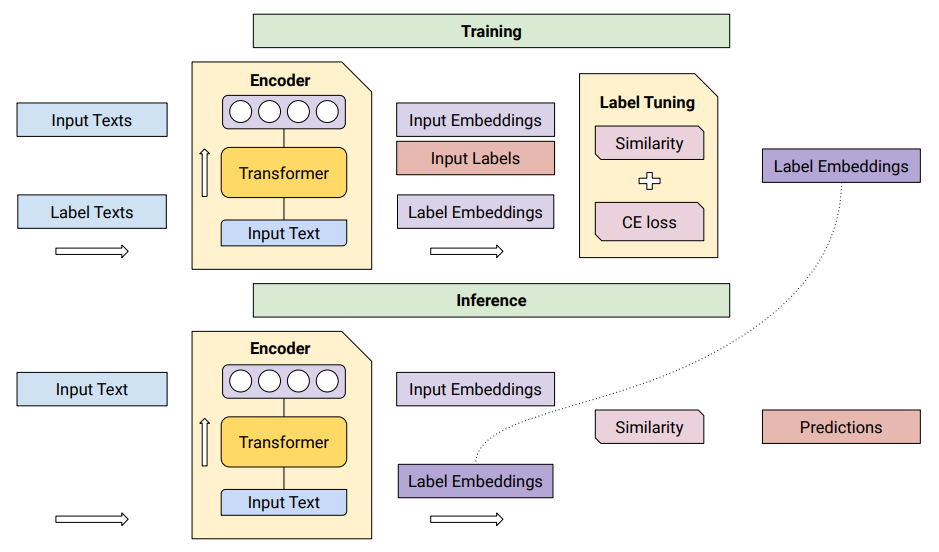
在训练时,输入和标签文本由编码器处理。然后Label Tuning(LT)使用交叉熵(CE)损失调优标签。在推理时,输入文本通过相同的编码器。然后使用调优的标签嵌入和相似度函数对每个标签进行评分。编码器保持不变,可以在多个任务之间共享。
在小样本学习的情况下,需要在小样本的基础上对模型进行调整。在基于梯度的小样本学习中,尝试提高带有标签的小样本的相似度分数。从概念上讲,希望增加每个文本及其正确标签之间的相似度,并减少每个其他标签之间的相似度。使用batch softmax作为目标:
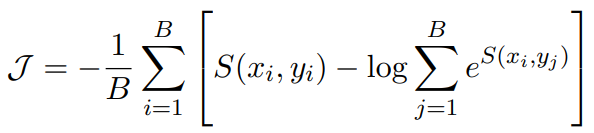
其中B是batch size,S(x, y) = f(x)·f(y)是当前模型f下输入x与标签文本y的相似度。在batch中,所有其他元素都作为负样本。为此,使每个batch中只包含每个标签的一个样本。这类似于典型的softmax分类目标。唯一的区别是f(yi)是在前向传播中计算的,而不是作为一个简单的参数查找。
定期微调的缺点是需要更新整个网络的权重。这导致每个新任务都需要较慢的训练和较大的内存需求,这反过来又增加了大规模部署新模型的挑战。作为一种替代方案,引入标签调优,它不改变编码器的权重。主要思想是首先预先计算每个类的标签嵌入,然后使用小样本对它们进行调优。有一个包含N对输入文本xi及其参考标签索引zi的训练集。预先计算输入文本的矩阵表示和标签的矩阵表示,X∈RN×d,Y∈RK×d,d为embedding的维数,K为标签集的大小。每个输入和标签组合的相似度分数定义为S = X × YT(S∈RN×K),并利用交叉熵进行调优。
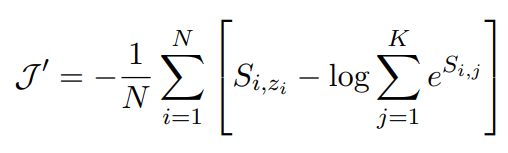
为了避免过拟合,使用范数添加了一个正则化,惩罚偏离初始标签嵌入太远的位置。另外,还通过在标签embedding中每个梯度步上mask一些项实现dropout。通过在小样本上4折交叉验证进行微调。要为每个调优模型存储的唯一信息是d维标签嵌入。
标签微调产生的模型比实际的微调精确度低。可以通过知识蒸馏来补偿。首先训练一个标准的微调模型,并使用该模型为未标注的样本生成标签分布。之后,将该数据集用于训练未调优模型的新标签embedding。这增加了该方法的训练成本,并增加了对未标注数据的额外要求,但保留了在推断时可以跨多个任务共享一个模型的优点。
论文证明了Cross Attention(CA)和Siamese Networks(SN)在不同的任务集和多种语言中提供了类似的结果。SNs的推理成本很低,因为标签embedding可以预先计算,而且与CA相比,SNs不随标签数量的增加而扩展。
只调优标签embeddings(LT)是可以替代微调(FT)方法的。当训练样本数量较少并且结合知识蒸馏时,即在小样本学习场景下,LT的性能接近FT。这与生产场景相关,因为它允许在任务之间共享相同的模型。LT是快速和可扩展的小样本学习下的一个选择。
论文:https://arxiv.org/pdf/2001.07676.pdf%EF%BC%89
代码:https://github.com/timoschick/pet
一些NLP任务通过使用预先训练好的带有“任务描述”的语言模型,可以以完全无监督的方式解决。虽然这种方法的性能不如监督方法,但本篇工作中表明,这两种思想可以结合起来:作者引入了Pattern-Exploiting Training(PET),一种半监督的训练过程,它将输入示例重新定义为完形句式短语,以帮助语言模型理解给定的任务。然后使用这些短语为大量无标签的样本分配软标签。最后,对得到的训练集进行标准监督训练。对于一些任务和语言,PET在低资源环境下的表现远远优于监督训练和强半监督方法。
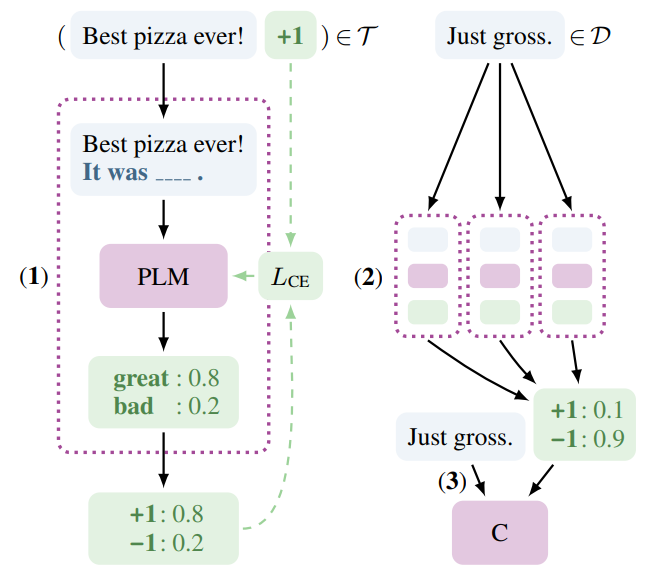
PET的工作过程分为三个步骤:
首先,针对每个模式,在小训练集T上对单独的PLM进行微调。
然后,使用所有模型的集合对一个大型的无标签数据集D进行软标签标注。
最后,在软标记数据集上训练标准分类器。
作者还设计了iPET,这是PET的迭代变体,该过程随着训练集规模的增加而重复。
M为预训练语言模型,词表为V,mask token包含在V中,任务A的标签集合L,输入序列x包含k个短语或句子。
定义一个模型函数(pattern)P,将x作为输入,输出包含一个mask token的短语或句子P(x),输出可以看作是一个完形填空。
定义一个映射函数(verbalizer)v,L—>V将每个标签映射到M的词汇表中的一个单词。
将(P, v)称为pattern-verbalizer pair(PVP)。
给定某个输入x,我们定义标签l∈L的分数为:
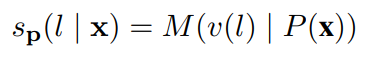
并使用softmax获得标签上的概率分布:
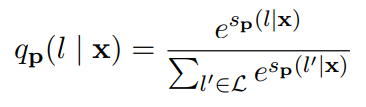
使用交叉熵作为微调的损失。
只使用少量样本进行训练,可能发生灾难性遗忘。对于基于PVP的PLM微调,核心仍然是一个语言模型,我们通过使用语言建模作为辅助任务来解决这个问题。LCE表示交叉熵损失,LMLM表示语言建模损失,计算最终损失为:
LMLM通常比LCE大得多,令α = 10−4
该方法面临的一个关键挑战是,在缺乏大型验证集的情况下,很难确定哪个PVPs表现良好。为了解决这个问题,使用了类似于知识蒸馏的策略。定义一个PVPs的集合P,直观地理解给定任务A的意义,按如下方法使用这些PVPs:
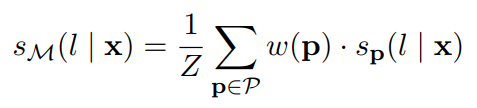
使用softmax将上述分数转换为概率分布q。使用T = 2得到适当的软分布。所有(x, q)对收集在一个(软标记的)训练集TC中。
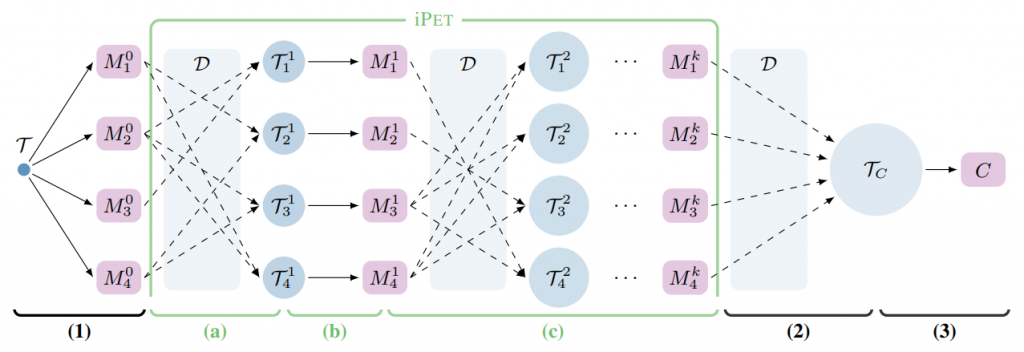
将所有单个模型的知识蒸馏到单个分类器中——意味着它们不能相互学习。由于有些模式的性能可能比其他模式差得多,因此最终模型的训练集TC可能包含许多标签错误的示例。为了弥补这个缺点,设计了iPET,它是PET的迭代变体。iPET的核心思想是在不断增大的数据集上训练几代模型。过程如图2所示。
经过训练k代PET模型,我们使用Mk创建TC和训练模型C在基本的PET。
为预训练的语言模型提供任务描述可以与标准的监督训练相结合。PET方法包括定义成对的完形填空问题模式(patterns)和语言表达器(verbalizers),这有助于利用预训练的语言模型中包含的知识来完成下游任务。对所有模式-语言化器对的模型进行微调,并使用它们创建大型的带注释的数据集,标准分类器可以在这些数据集上进行训练。当初始训练数据量有限时,PET比标准监督训练和强半监督方法有很大的改进。
论文:https://aclanthology.org/2022.acl-long.570.pdf
代码:https://github.com/amazon-research/label-aware-pretrain
在文本分类任务中,有用的信息编码在标签名称中。标签语义感知系统利用这些信息在微调和预测期间提高了文本分类性能。然而,标签语义在预训练中的应用还没有得到广泛的探讨。因此,作者提出标签语义感知预训练(LSAP)来提高文本分类系统的泛化和数据效率。LSAP通过对来自不同领域的带有标签的句子进行二次预训练,将标签语义整合到预训练生成模型中。由于预训练需要大量的数据,作者开发了一个过滤和标注pipline来自动从未标记的文本创建sentence-label对。
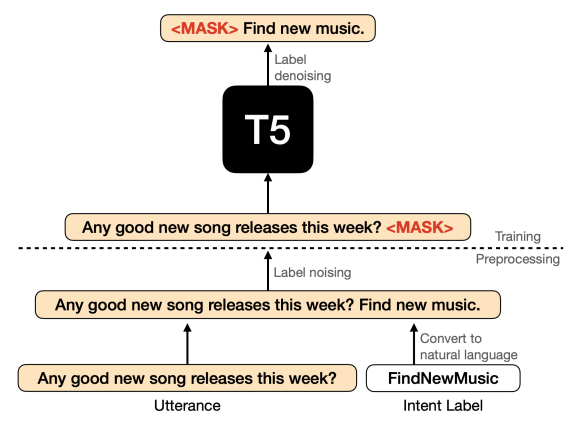
LSAP方法在(伪)标记样本的大规模集合上使用T5进行二次预训练。
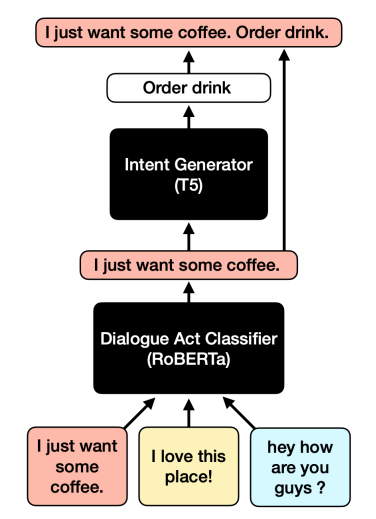
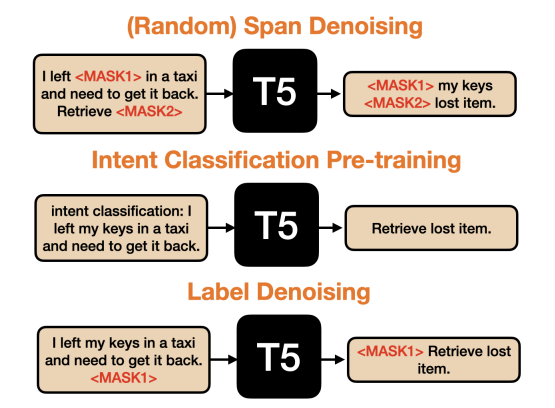
提出了一种利用标签中固有语义信息的预训练方法。提高了跨域小样本文本分类性能,同时在全资源设置下保持高性能。
论文:https://arxiv.org/pdf/2108.13161.pdf
代码:https://github.com/zjunlp/DART
优化prompt是提高预训练语言模型在小样本学习中是很有必要的。离散标记的模板可能陷入局部最优,并且不能充分表示特定的类别。为了提高prompt方法在各个领域的适用性,论文提出了可微分提示(DifferentiAble pRompT),简称DART,可以减少提示工程的要求。
利用语言模型中的一些参数作为模板和标签标记,并通过反向传播对它们进行优化,而不引入模型之外的其他参数。因为有限样本的微调可能会受到不稳定性的影响。进一步引入了一个辅助流畅性约束对象,以确保prompt嵌入之间的关联。减少提示工程(包括模板和标签)和外部参数优化。此外,该算法可以使用任何预训练的语言模型并可扩展到广泛的分类任务。
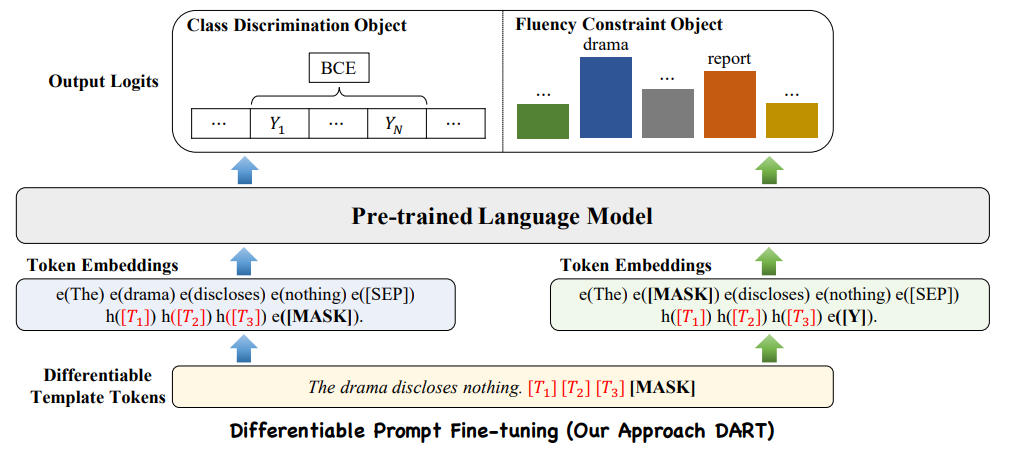
由于语言token是离散变量,用token搜索找到最优提示并不简单,很容易陷入局部极小值.为了克服这些限制,作者利用伪标记(pseudo tokens)构造模板,然后用反向传播优化它们。可微模板优化可以获得超越原始词汇V的表达模板。将模板映射为如下形式:
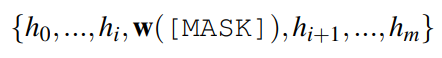
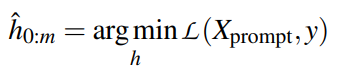
DART利用辅助流畅性约束目标将提示嵌入彼此关联起来,从而促进模型专注于上下文表示学习。
暴力强制标签搜索:(1)由于验证集通常非常大,需要进行多轮评估,计算量大且繁琐。(2)可扩展性差,随着类数的增加呈指数型增长,因此很难处理。此外,类别的标签包含丰富而复杂的语义知识,一个离散的标记可能不足以表示这些信息。
DART将Yj映射到一个连续词汇空间,如下所示:
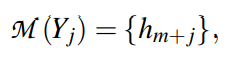
为了避免优化任何外部参数,{h1,…,hm,..,hm+n}替换为未使用的token
由于提示模板中的伪标记必须彼此相互依赖,作者引入了辅助的流畅性约束训练,而没有优化任何其他参数。总体而言,有两个目标:the class discrimination objective(LC)和the fluency constraint objective(LF)
是对句子进行分类的主要目标,CE是交叉熵损失函数。
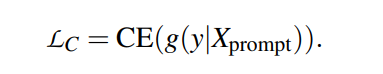
为了确保模板标记之间的关联,并维护从PLMs继承来的语言理解能力,作者利用MLM的流畅性约束对象,对输入语句中的一个标记进行随机掩码,并进行掩码语言预测。该语言模型可以通过模板标记之间的丰富关联获得更好的上下文表示。
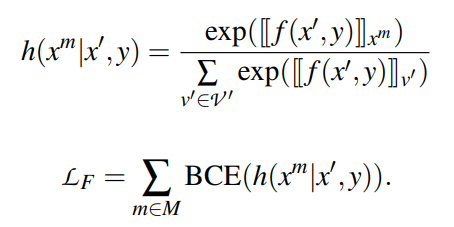
为了小样本微调的不稳定性,作者联合优化模板和标签。
论文介绍了一种简单而有效的优化方法DART,它改进了fast-shot learning预训练语言模型。与传统的优化方法相比,所提出的方法可以在小样本的情况下产生令人满意的改进。该方法还可用于其他语言模型(如BART),并可扩展到其他任务,如意图检测和情感分析。
论文:https://arxiv.org/pdf/2203.12277.pdf
代码:https://github.com/universal-ie/UIE
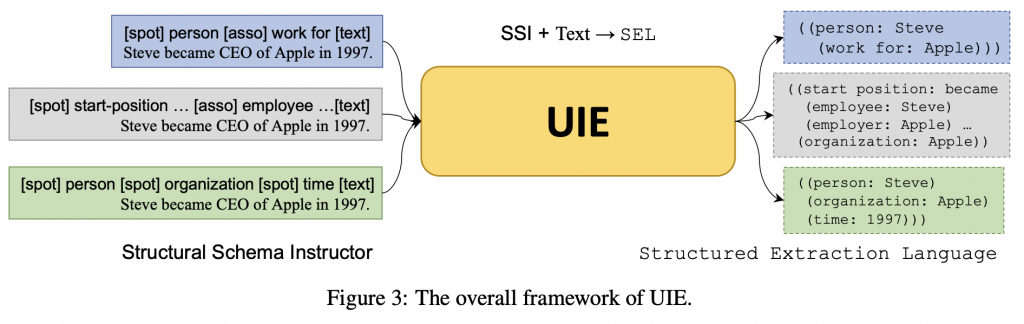

论文:https://arxiv.org/abs/2108.06332
代码:https://github.com/zhouj8553/FlipDA
大多数以前的文本数据增强方法都局限于简单的任务和弱基线。作者在困难任务(小样本的自然语言理解)和强基线(具有超过10亿个参数的预训练模型)上做数据增强。
在困难任务和强基线模型下,很多以前的文本数据增强方法,最多只带来边际增益,有时会大大降低性能。在许多情况下,使用数据增强会导致性能不稳定,甚至进入故障模式。
作者提出了一种新的数据增强方法FlipDA,该方法联合使用生成模型和分类器来生成标签翻转数据。FlipDA的核心思想是发现生成标签翻转数据比生成标签保留数据对性能更重要。与保留原始标签的增强数据相比,标签翻转数据往往大大提高了预训练模型的泛化能力。实验表明,FlipDA在有效性和鲁棒性之间实现了很好的权衡,它在不影响其他任务的同时,极大地改善了许多任务。在小样本的设定下,有效性和鲁棒性是数据增强两个关键要求。
数据增强应该在某些特定任务上显著提高性能。
1、在不使用数据增强的条件下,训练分类器(对预训练的模型进行微调)
2、生成标签保留和标签翻转的增强样本
首先使用完形填空模式将x和y组合成一个序列,然后随机mask一定百分比的输入的tokens。然后使用预训练的T5模型来填补空白,形成一个新的样本。如果T5不能预测出新样本的y值,删除这个样本是有益的。使用T5生成增强样本确实引入了额外的知识并减少了语法错误,但仅使用T5进行增强而不进行标签翻转和选择效果不佳。
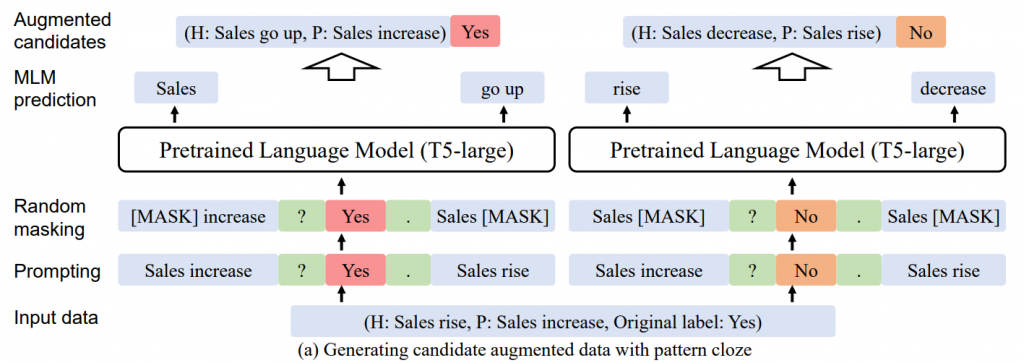
3、使用分类器为每个标签选择概率最大的生成样本
Si 是从原始样本 (xi , yi ) 增强的数据集合,y‘ 不等于 yi
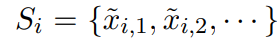
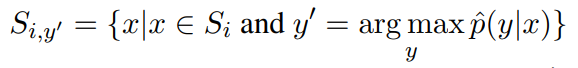
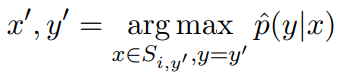
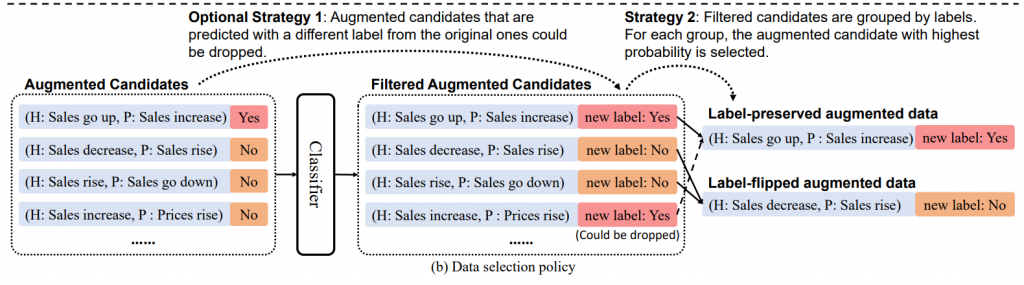
4、用原始样本和附加的增强样本重新训练分类器
数据增强方法在任何时候不应该遇到故障模式(failure mode)。故障模式在小样本学习中很常见,在这种情况下,一些微小的更改可能会导致性能大幅下降。
大多数增强方法都是基于标签保留的假设,而自动方法生成标签保留的样本是一个挑战。如果模型在保持标签的假设下,在有噪声的增强数据上进行训练,性能下降是可能的。作者将噪音数据总结为两类,一类是导致理解困难的语法错误,另一类是改变标签关键信息的修改。
标签翻转提高了小样本的泛化性,论文提出具有自动标签翻转和数据选择的FilpDA算法。实验证明了FlipDA的优越性,在有效性和鲁棒性方面都优于以往的方法。在未来,从理论上理解在现有数据点附近生成标签翻转数据为什么以及如何提高泛化将是至关重要的。此外,增加增强数据生成的多样性和质量也是一个重要的长期目标。
bash scripts/run_pet.sh <task_name> <gpu_id> baseline结果会保存在results/baseline/pet/<task_name>_albert_model/result_test.txt文件中
CUDA_VISIBLE_DEVICES=0 python -m genaug.total_gen_aug --task_name <task_name> --mask_ratio <mask_ratio> --aug_type <aug_type> --label_type <label_type> --do_sample --num_beams <num_beams> --aug_num <aug_num>备选方案:使用不带分类器的增强文件运行基线模型,如果希望将增强文件中的所有增强数据添加到模型中(不希望根据训练过的分类器更改标签或过滤增强样本),可以运行如下命令。
bash scripts/run_pet.sh boolq 0 <augmented_file_name>如果允许分类器对增广数据的标签进行校正,则执行如下命令,其中<augmented_file_name>是增强文件名,例如,”t5_flip_0.5_default_sample0_beam1_augnum10″。
bash scripts/run_pet.sh boolq 0 genaug_<augmented_file_name>_filter_max_eachla如果不允许分类器纠正增强数据的标签,则运行如下命令
bash scripts/run_pet.sh boolq 0 genaug_<augmented_file_name>_filter_max_eachla_sep选择哪个命令取决于增强模型和分类模型的relative power。如果增强模型足够精确,选择带有“sep”的命令会更好。否则,选择第一个。如果不确定,就两种都试试。