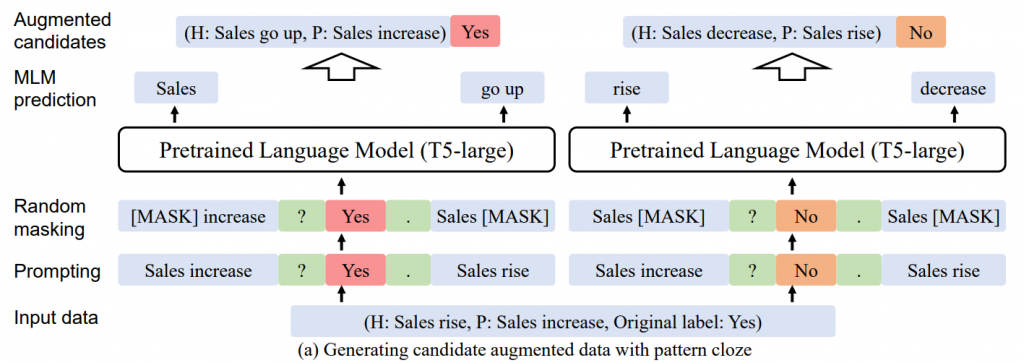
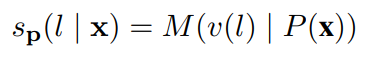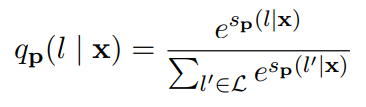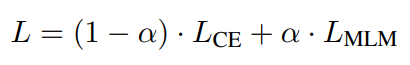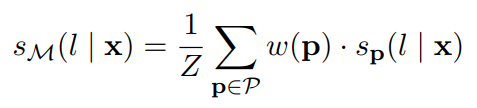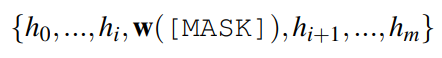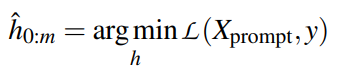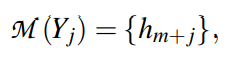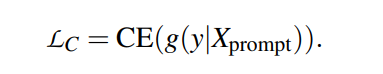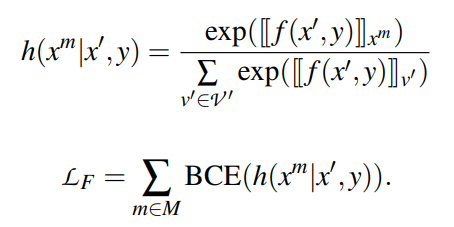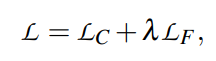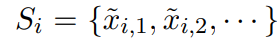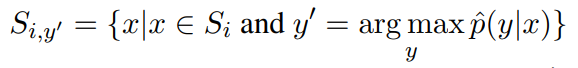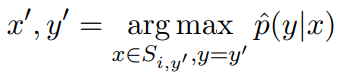前言
论文:https://arxiv.org/pdf/2203.14655v2.pdf
代码:https://github.com/symanto-research/few-shot-learning-label-tuning
摘要
在训练数据很少或没有训练数据的情况下构建文本分类器的问题,通常称为零样本和小样本文本分类。近年来,一种基于神经文本蕴涵模型的方法已被发现在不同的任务范围内提供强大的结果。在这项工作中表明,通过适当的预训练,嵌入文本和标签的Siamese网络提供了一个有竞争力的替代方案。这些模型大大降低推理成本:标签数量恒定,而不是线性。此外,还引入了标签调优,是一种简单且计算效率高的方法,它允许通过仅更改标签嵌入来在少量设置中适应模型。虽然提供比模型微调更低的性能,但这种方法具有体系结构上的优势,即单个编码器可以由多个不同的任务共享。
动机
- 对于文本数据,任务的标签通常是通过文本形式来实现的,可以是标签的名称,也可以是简明的文本描述。
- Cross Attention(CA)和Siamese Networks(SNs)还通过对小样本的模型进行微调来支持小样本学习。这通常是通过更新模型的所有参数来完成的,导致不能在不同任务之间共享模型。
- 作者提出Label Tuning(LT)作为完全微调的替代方案,它允许对许多任务使用相同的模型,从而极大地增加了方法的可伸缩性。
模型
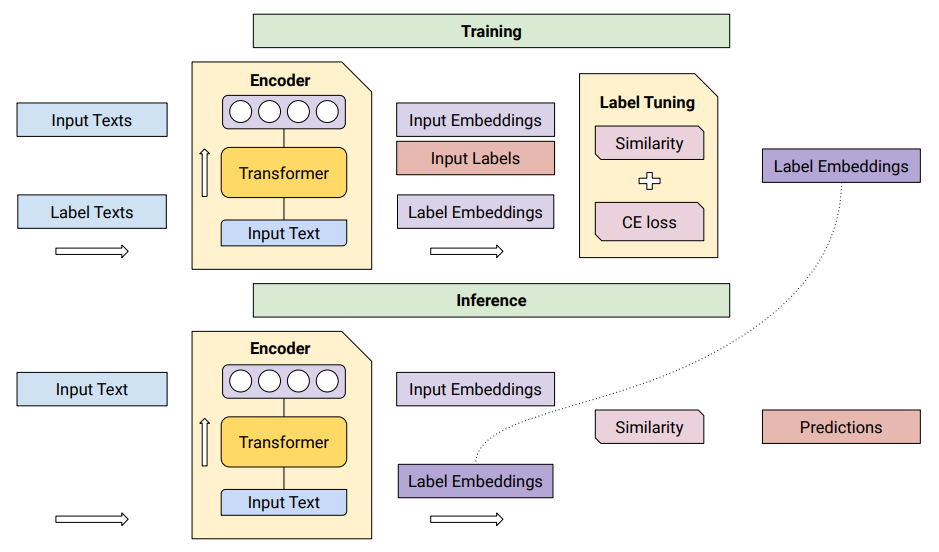
在训练时,输入和标签文本由编码器处理。然后Label Tuning(LT)使用交叉熵(CE)损失调优标签。在推理时,输入文本通过相同的编码器。然后使用调优的标签嵌入和相似度函数对每个标签进行评分。编码器保持不变,可以在多个任务之间共享。
方法
Fine-Tuning
在小样本学习的情况下,需要在小样本的基础上对模型进行调整。在基于梯度的小样本学习中,尝试提高带有标签的小样本的相似度分数。从概念上讲,希望增加每个文本及其正确标签之间的相似度,并减少每个其他标签之间的相似度。使用batch softmax作为目标:
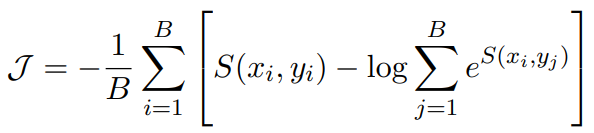
其中B是batch size,S(x, y) = f(x)·f(y)是当前模型f下输入x与标签文本y的相似度。在batch中,所有其他元素都作为负样本。为此,使每个batch中只包含每个标签的一个样本。这类似于典型的softmax分类目标。唯一的区别是f(yi)是在前向传播中计算的,而不是作为一个简单的参数查找。
Label Tuning
定期微调的缺点是需要更新整个网络的权重。这导致每个新任务都需要较慢的训练和较大的内存需求,这反过来又增加了大规模部署新模型的挑战。作为一种替代方案,引入标签调优,它不改变编码器的权重。主要思想是首先预先计算每个类的标签嵌入,然后使用小样本对它们进行调优。有一个包含N对输入文本xi及其参考标签索引zi的训练集。预先计算输入文本的矩阵表示和标签的矩阵表示,X∈RN×d,Y∈RK×d,d为embedding的维数,K为标签集的大小。每个输入和标签组合的相似度分数定义为S = X × YT(S∈RN×K),并利用交叉熵进行调优。
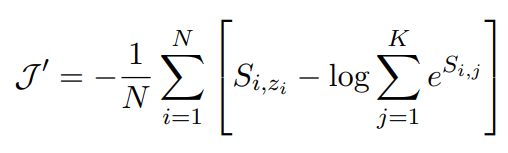
为了避免过拟合,使用范数添加了一个正则化,惩罚偏离初始标签嵌入太远的位置。另外,还通过在标签embedding中每个梯度步上mask一些项实现dropout。通过在小样本上4折交叉验证进行微调。要为每个调优模型存储的唯一信息是d维标签嵌入。
Knowledge Distillation
标签微调产生的模型比实际的微调精确度低。可以通过知识蒸馏来补偿。首先训练一个标准的微调模型,并使用该模型为未标注的样本生成标签分布。之后,将该数据集用于训练未调优模型的新标签embedding。这增加了该方法的训练成本,并增加了对未标注数据的额外要求,但保留了在推断时可以跨多个任务共享一个模型的优点。
结论
论文证明了Cross Attention(CA)和Siamese Networks(SN)在不同的任务集和多种语言中提供了类似的结果。SNs的推理成本很低,因为标签embedding可以预先计算,而且与CA相比,SNs不随标签数量的增加而扩展。
只调优标签embeddings(LT)是可以替代微调(FT)方法的。当训练样本数量较少并且结合知识蒸馏时,即在小样本学习场景下,LT的性能接近FT。这与生产场景相关,因为它允许在任务之间共享相同的模型。LT是快速和可扩展的小样本学习下的一个选择。