论文:https://github.com/zhongziyue/SDEA/tree/main/paper
代码:https://github.com/zhongziyue/SDEA
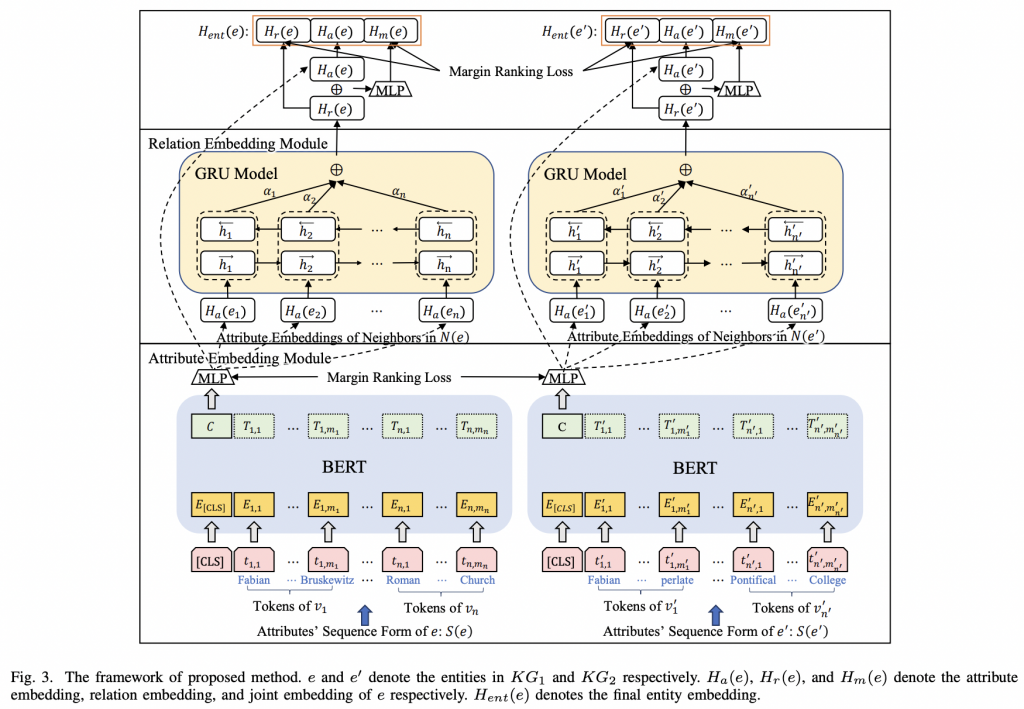
SDEA一种语义驱动的实体嵌入方法,用于实体对齐。SDEA由属性嵌入和关系嵌入两个模块组成。属性嵌入通过预训练的基于transformer的语言模型从属性值中捕获语义信息。关系嵌入使用带有注意力机制的GRU模型选择性地聚合邻居节点的语义信息。属性嵌入和关系嵌入都以语义为驱动,在实体之间建立桥梁。
为了更好地捕捉实体内在的语义(主要体现在长文本属性值中),并有效识别邻居实体在对齐过程中的贡献,提出了一种语义驱动的实体嵌入方法SDEA。该文采用两个嵌入模块,即属性嵌入和关系嵌入。在属性嵌入模块中,使用基于transformer的预训练语言模型来获得每个实体的初始嵌入。最重要的是,该模块捕获了细粒度语义和实体的直接关联。进一步,关系嵌入模块通过注意力机制从属性嵌入的细粒度语义中学习邻近实体的贡献,并选择性地聚合来自邻近实体的信息。此外,从属性嵌入(保留实体的语义)和关系嵌入(聚合邻居实体的语义)进行联合表示学习,以发现实体之间的间接关联。
SDEA框架
属性嵌入模块(Attribute Embedding Module)
属性嵌入模块旨在从实体的属性值中捕获实体之间的语义关联。属性值不仅包括短文本和数字,还包括长句子。从属性值中捕获语义信息一直是一个挑战。为了解决这个问题,使用Transformer,该模型在捕获文本语义信息方面达到了最先进的性能,以处理文本中的异构性。此外,为了处理不同KG模式的异构性,通过将实体的所有属性值组合为一个整体来捕获细粒度语义,然后捕获两个实体之间的语义关联。将属性嵌入形式化为BERT的下游任务,即对预训练的BERT进行微调,将实体ei的属性值编码为属性嵌入Ha(ei)在以下两个阶段。
1)数据预处理:此阶段旨在将实体ei的属性值转换为序列,即一系列tokens,然后可以将其输入到BERT模型中。算法1描述了该步骤的总体过程。

例如,下图说明了算法1中的过程。

2)属性编码:此阶段将前一步生成的序列作为输入,目的是通过BERT模型将序列转换为嵌入。使用预训练的BERT模型和MLP (Multi-Layer Perceptron)层,通过对实体ei的属性序列S(ei)进行编码,得到属性嵌入向量Ha(ei)。
关系嵌入模块(Relation Embedding Module)
在关系嵌入模块中,使用基于GRU的注意机制来建模邻居的贡献,并选择性地聚合这些信息。直观地说,给定一个实体ei,它的邻居ej的贡献将取决于ei的其他邻居。替代方法包括平均邻居的嵌入、池化和直接使用注意机制。相比之下,Bidirectional GRU (BiGRU)模型能够捕捉ei不同邻居之间的相关性,从而可以根据上下文信息(周围邻居)对不同实体的同一邻居的不同贡献进行建模。
用BiGRU捕获邻居间的相关性,直观地,将实体ei的所有邻居作为BiGRU模型的输入序列。注意机制使模型能够利用每个邻居的重要性,从邻居中提取最相关的信息。
联合实体表示(Joint Entity Representation)
给定一个实体ei,属性嵌入模块和关系嵌入模块分别计算其属性嵌入Ha(ei)和关系嵌入Hr(ei),分别从属性和邻居中获取信息。为了联合建模来自属性和邻居的信息,计算了一个联合表示Hm(ei),通过一个MLP层将Ha(ei)和Hr(ei)结合在一起。
因此,三个嵌入Ha(ei)、Hr(ei)和Hm(ei),分别捕获属性信息、邻居信息以及联合属性和邻居信息。最后的实体嵌入内容(ei)是这些嵌入的连接,它捕获信息的所有三个方面。