摘要
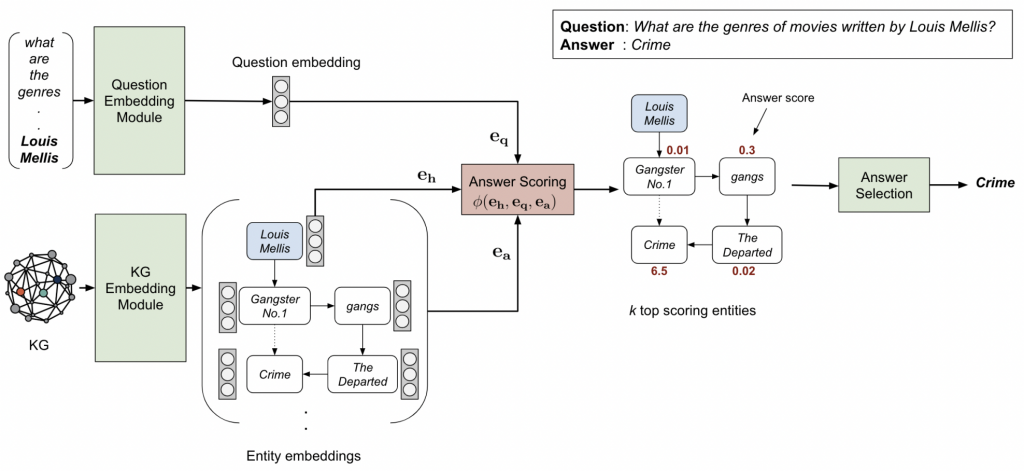
知识库问答(KBQA)的目的是在外部知识库的帮助下回答自然语言问题。其核心思想是找到问题背后的内部知识与知识库中已知三元组之间的联系。传统的KBQA任务piplines包含实体识别、实体链接、答案选择等步骤。在这种pipline方法中,任何过程中的错误都会不可避免地传播到最终的预测。为了解决这一问题,论文提出了一种基于预训练语言模型的语料库生成-检索方法(Corpus Generation – Retrieve Method,CGRM)。主要的创新之处在于新方法的设计。其中,知识增强T5 (kT5)模型旨在基于知识图谱三元组生成自然语言QA对,并通过检索合成数据集直接求解QA。该方法可以从PLM中提取更多的实体信息,提高精度,简化过程。我们在NLPCC-ICCPOL 2016 KBQA数据集上测试了我们的方法,结果表明该方法提高了KBQA的性能,并且与最先进的方法相比具有竞争力。
背景和挑战
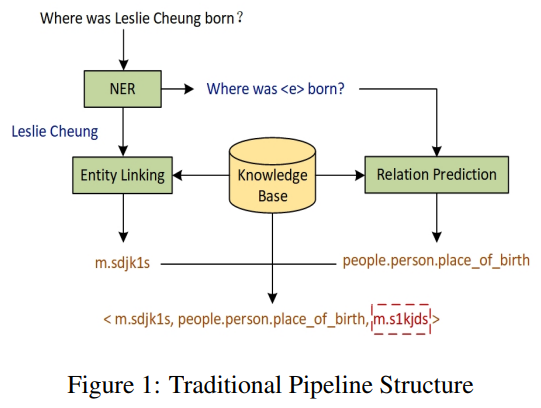
问答系统是自然语言处理领域长期以来的研究热点。一个方向是将已有的知识库用于自然语言问题,称为知识库问答(Knowledge Base Question Answering, KBQA)。目前KBQA的主流方法是将当前问句的实体链接到KBQA实体中,利用句子中出现的关系归纳到知识图谱中得到最终答案。目前,KBQA任务主要通过一组分步处理的pipline来解决,包括实体识别、关系抽取、实体链接、答案选择,如图1所示。在应用上述pipline方法时,中途发生的任何错误都会影响到后续所有的pipline链接,从而在很大程度上降低整个KBQA系统的性能。