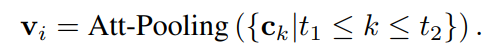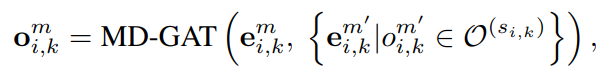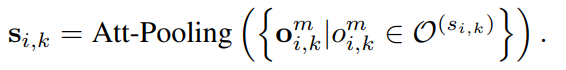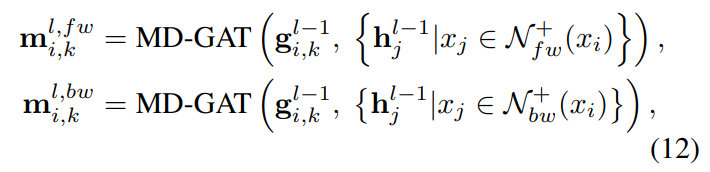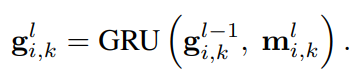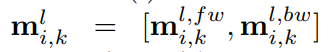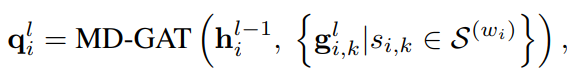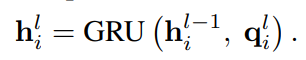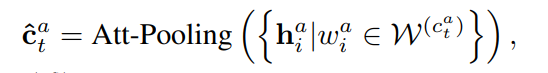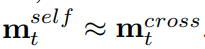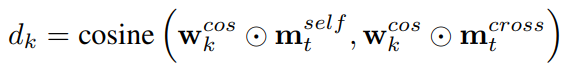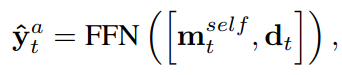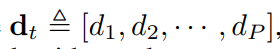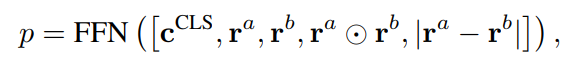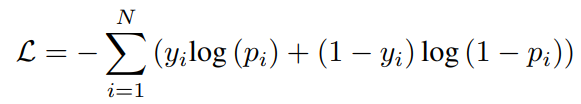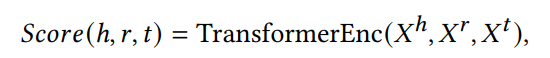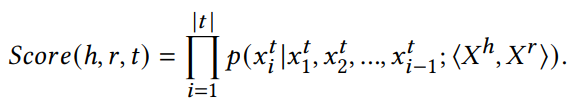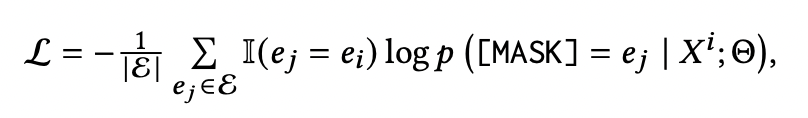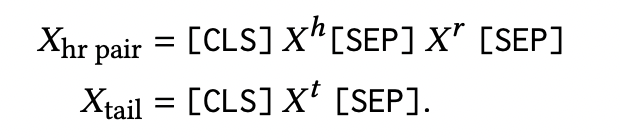首先,在对短文本进行概念化时,由于实体的歧义性或KBs中的噪声,容易引入一些不恰当的概念。例如,在短文本S2:“Alice has been using Apple for 10 more years”中,从KB中获取了Apple的fruit和mobile phone两个概念。显然,fruit在这里不是一个合适的概念,这是由于Apple的模糊性造成的。
其次,需要考虑概念的粒度和概念的相对重要性。例如,在短文本S3:“Bill Gates is one of the co-founders of Microsoft”中,从KB中检索了person和entrepreneur of Bill Gates的概念。虽然它们都是正确的概念,但企业家比人更具体,在这种情况下应该被赋予更大的权重。之前的工作利用网络规模的KBs来丰富短文本表示,但没有仔细解决这两个问题。
为了解决这两个问题,该文引入注意力机制,提出了基于知识驱动注意力的深度短文本分类(STCKA)。注意力机制被广泛用于获取向量的权重,在许多NLP应用中,包括机器翻译、摘要生成和问答。针对第一个问题,使用面向短文本的概念注意力(Concept towards Short Text,CST)来衡量短文本与其对应概念之间的语义相似度。该模型赋予S2中mobile phone概念较大的权重,因为它与短文本的语义相似度高于fruit概念。针对第二个问题,使用面向概念集的注意力(Concept towards Concept Set,C-CS)来探索每个概念相对于整个概念集的重要性。模型为S3中的概念企业家分配了更大的权重,这对特定的分类任务更具区分性。
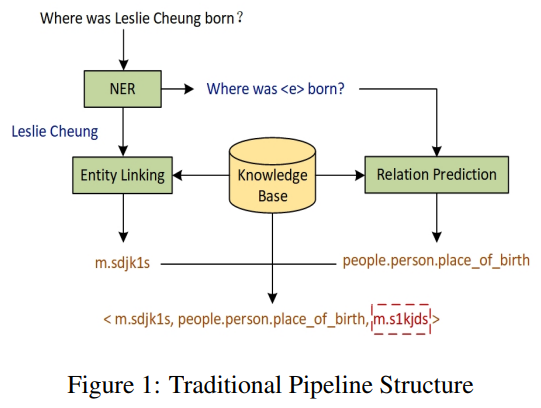
问答系统是自然语言处理领域长期以来的研究热点。一个方向是将已有的知识库用于自然语言问题,称为知识库问答(Knowledge Base Question Answering, KBQA)。目前KBQA的主流方法是将当前问句的实体链接到KBQA实体中,利用句子中出现的关系归纳到知识图谱中得到最终答案。目前,KBQA任务主要通过一组分步处理的pipline来解决,包括实体识别、关系抽取、实体链接、答案选择,如图1所示。在应用上述pipline方法时,中途发生的任何错误都会影响到后续所有的pipline链接,从而在很大程度上降低整个KBQA系统的性能。
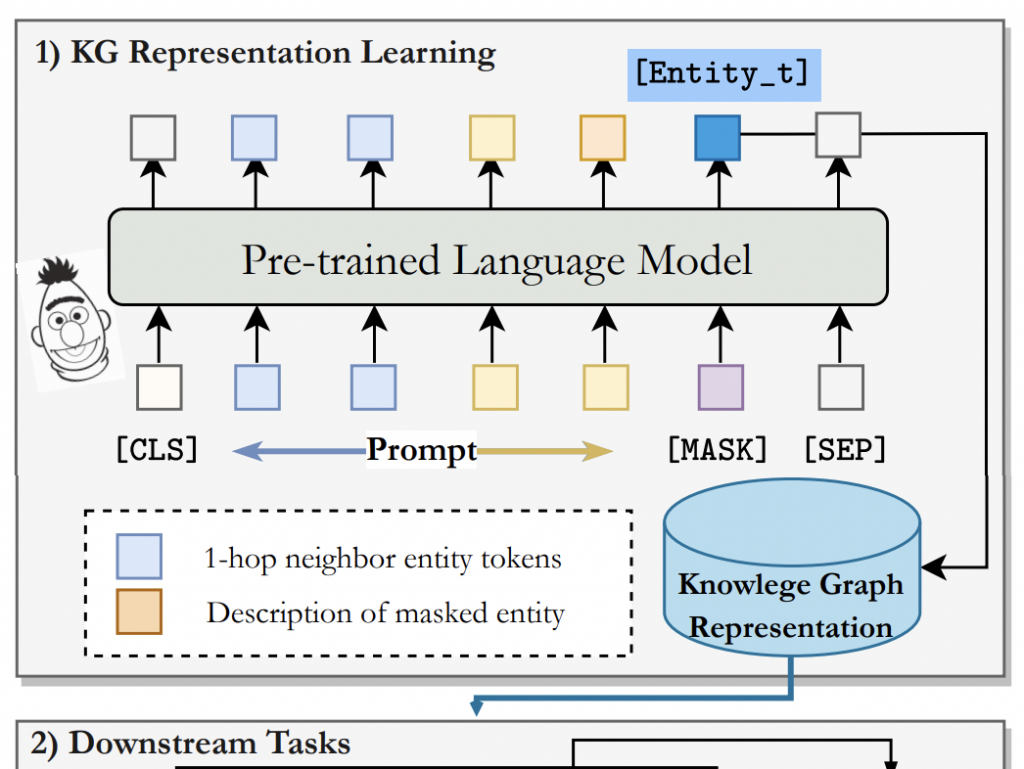
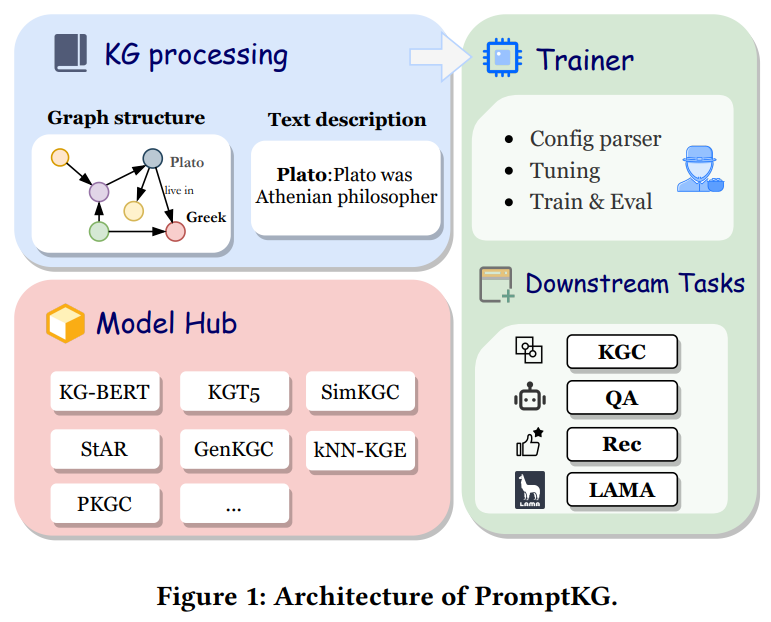
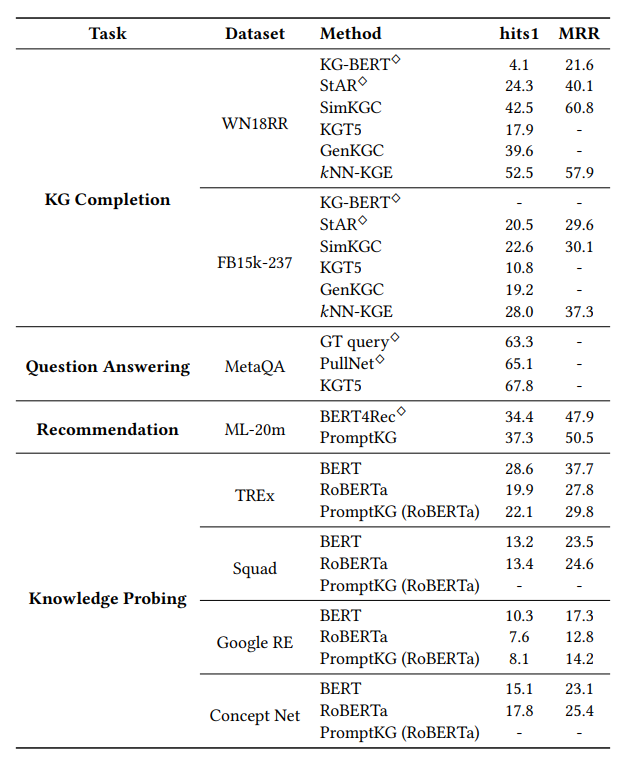
PromptKG由一个模型中心组成,支持许多基于文本的知识图谱表示模型。例如,KG-BERT使用BERT对三元组及其描述进行评分。但KG-BERT具有较高的时间复杂度,StAR和SimKGC都引入了一种基于塔的方法( a tower-based method)来预计算实体嵌入并高效地检索top-?实体。此外,GenKGC和KGT5将知识图谱补全视为序列到序列(seq2seq)的生成方法。此外,?NN-KGE是一种通过k近邻线性插值其实体分布的知识图谱表示模型。