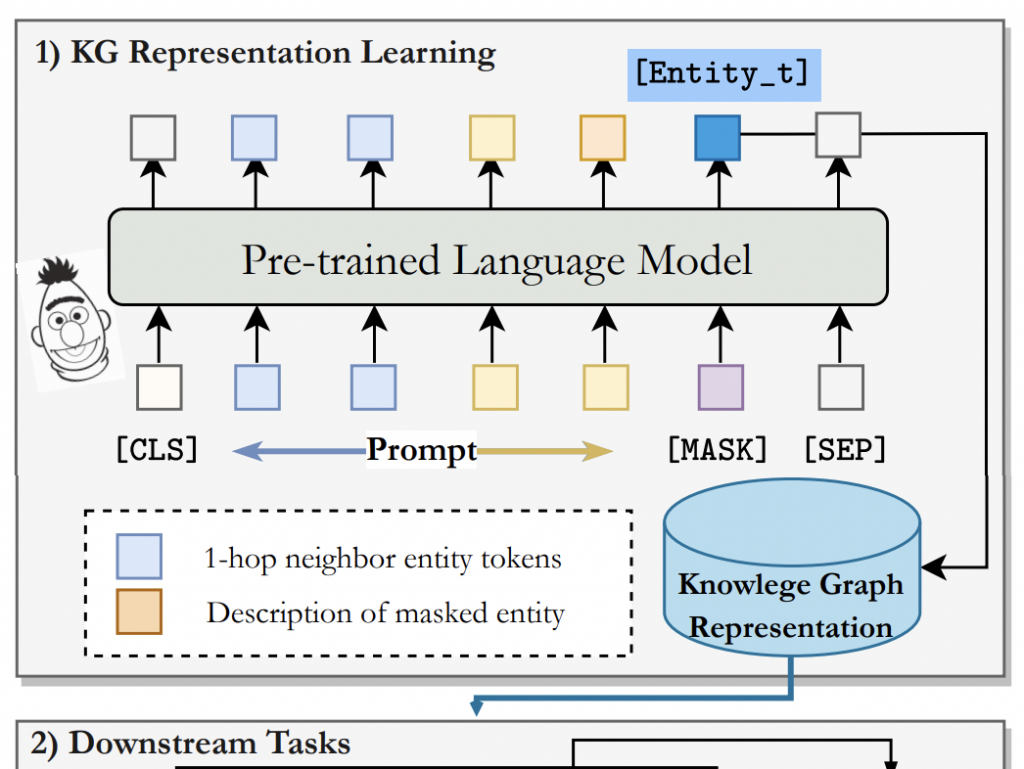
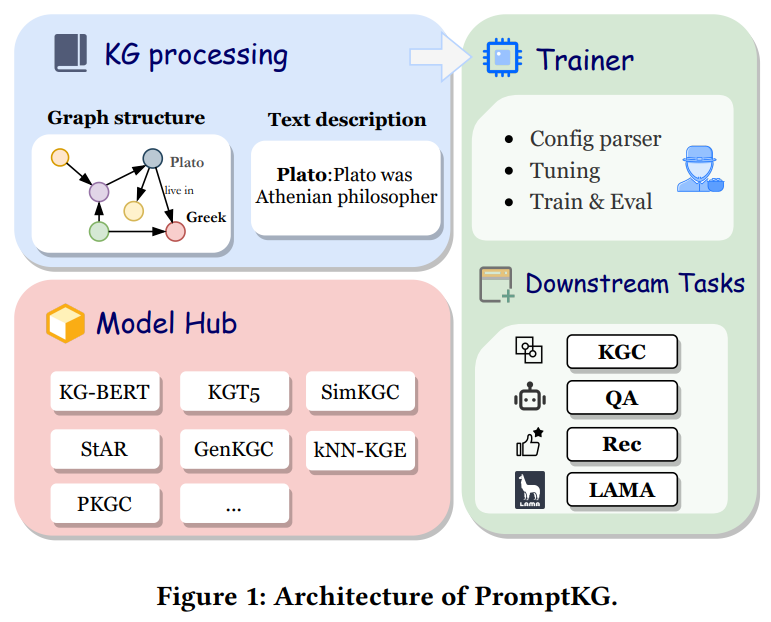
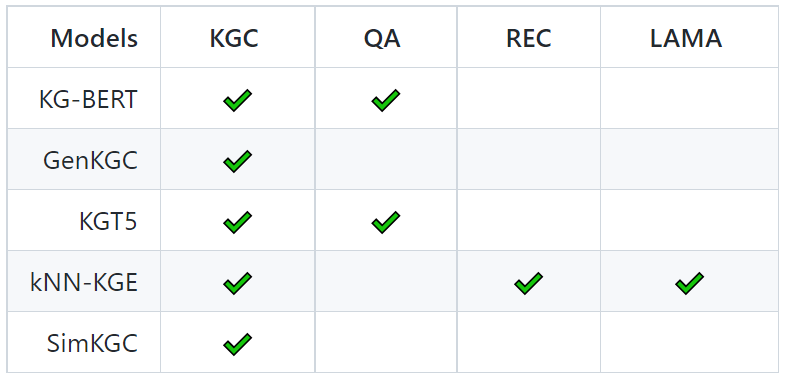
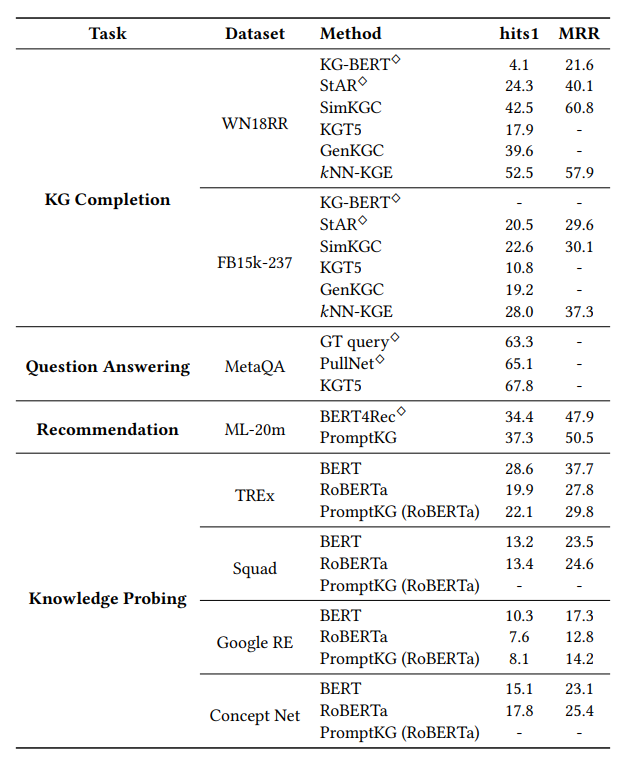
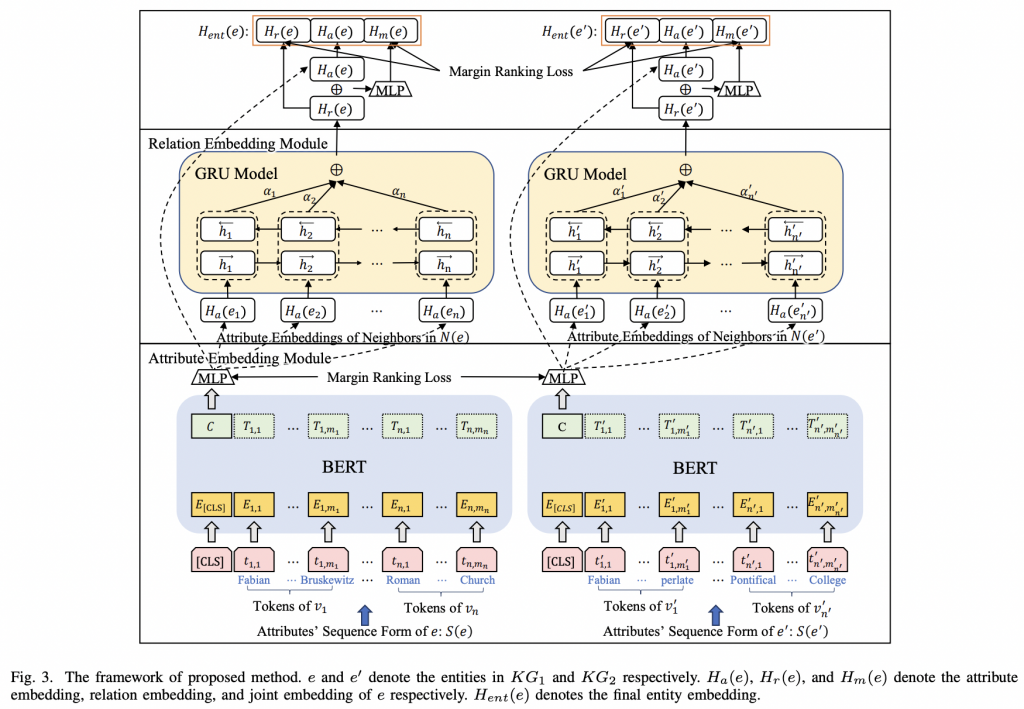
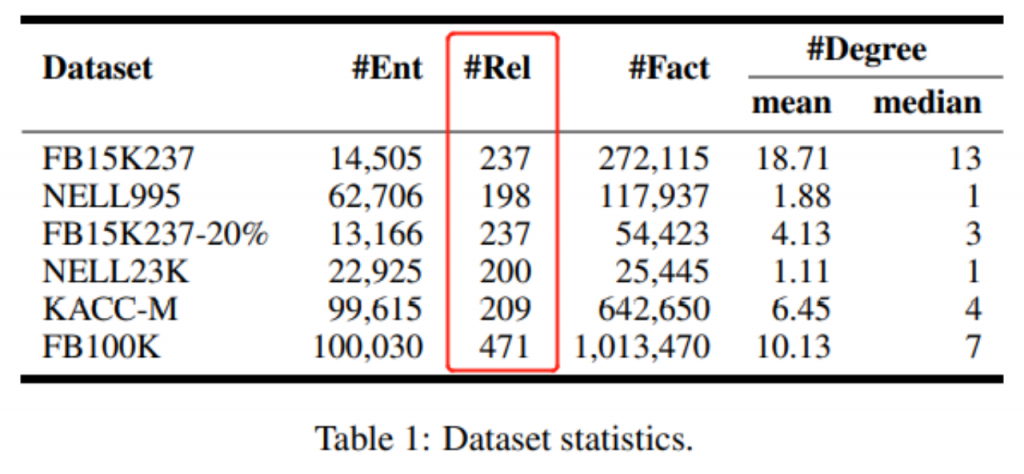
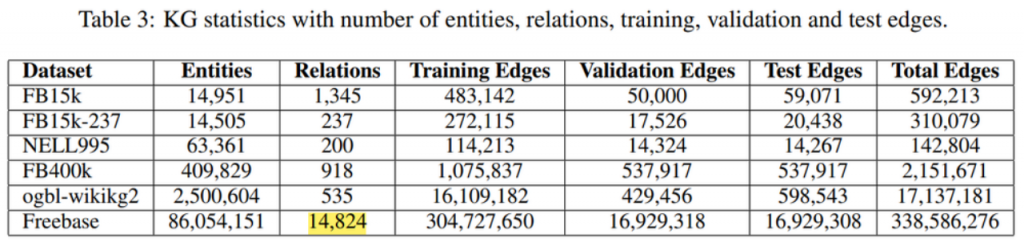
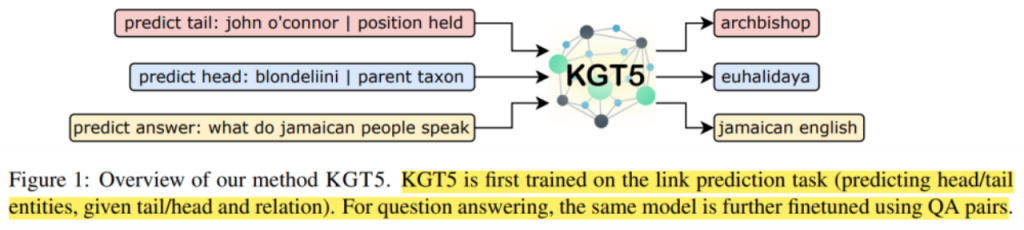
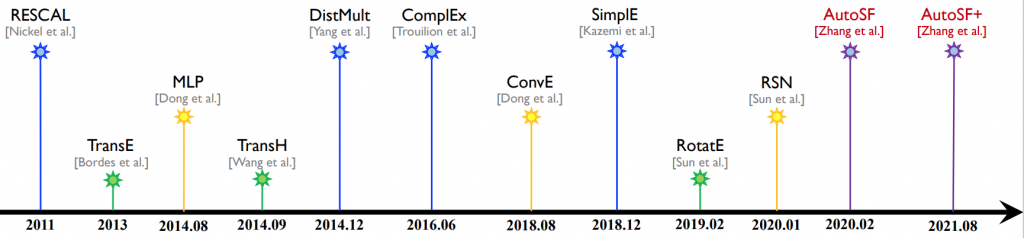
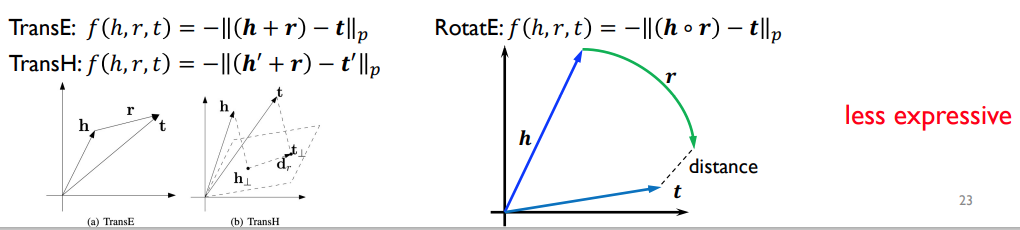
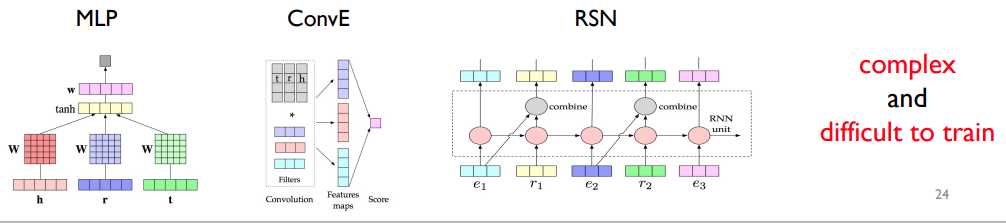
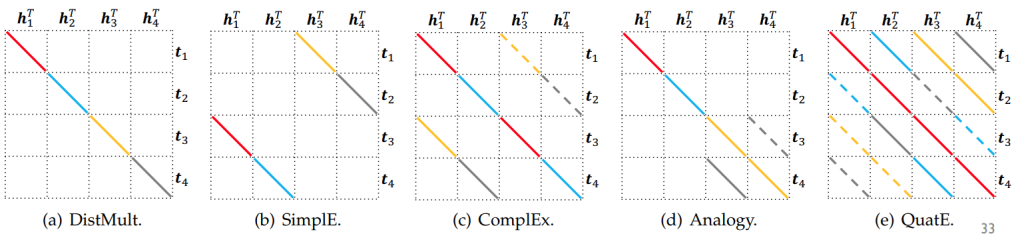
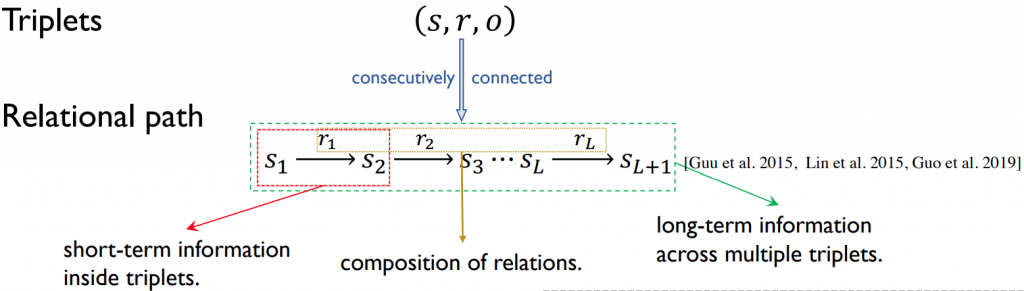
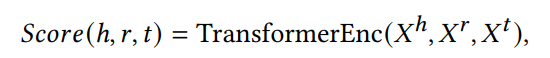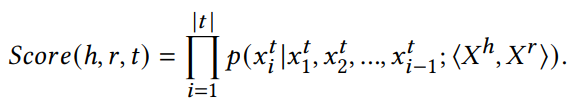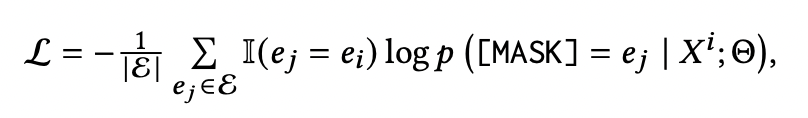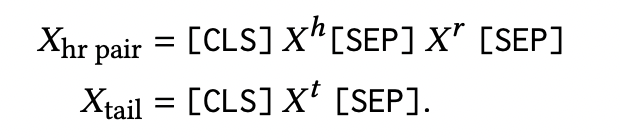PromptKG由一个模型中心组成,支持许多基于文本的知识图谱表示模型。例如,KG-BERT使用BERT对三元组及其描述进行评分。但KG-BERT具有较高的时间复杂度,StAR和SimKGC都引入了一种基于塔的方法( a tower-based method)来预计算实体嵌入并高效地检索top-?实体。此外,GenKGC和KGT5将知识图谱补全视为序列到序列(seq2seq)的生成方法。此外,?NN-KGE是一种通过k近邻线性插值其实体分布的知识图谱表示模型。
R2RML is a customizable language to map a relational database to RDF.
ps:可自定义的映射。
RDB2RDF工具
Ontop
Ontop is a Virtual Knowledge Graph system. It exposes the content of arbitrary relational databases as knowledge graphs. These graphs are virtual, which means that data remains in the data sources instead of being moved to another database.
Ontop translates SPARQL queries expressed over the knowledge graphs into SQL queries executed by the relational data sources. It relies on R2RML mappings and can take advantage of lightweight ontologies.
SparqlMap
A SPARQL to SQL rewriter based on R2RML specification.
Triplify is a small PHP plugin for Web applications, which reveals the semantic structures encoded in relational databases by making database content available as RDF, JSON or Linked Data.
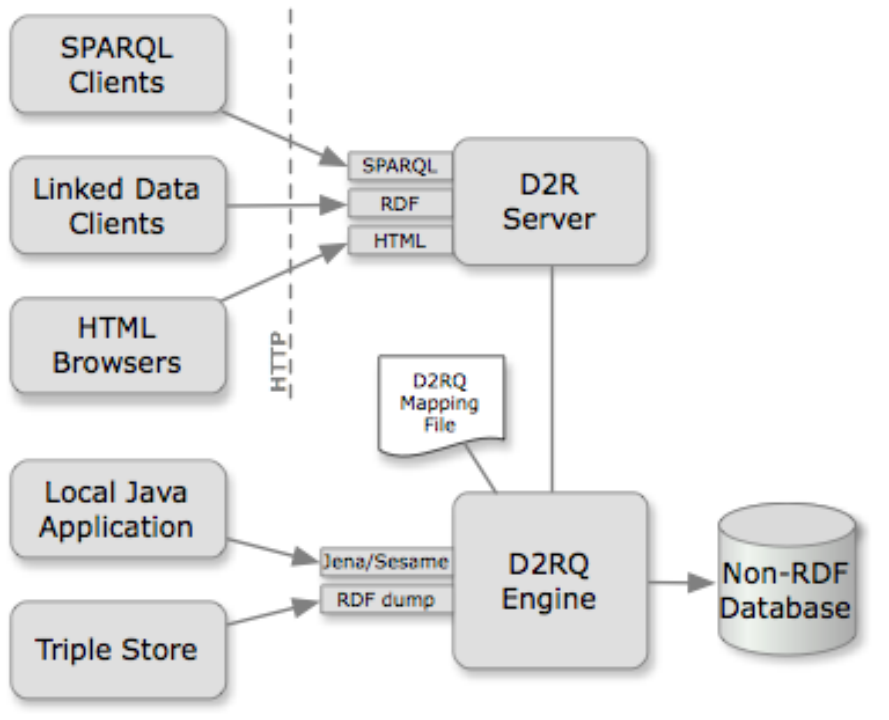
D2RQ
D2RQ的官方介绍是Accessing Relational Databases as Virtual RDF Graphs。http://d2rq.org/