raise error.APIConnectionError( openai.error.APIConnectionError: Error communicating with OpenAI: HTTPSConnectionPool(host=’api.openai.com’, port=443): Max retries exceeded with url: /v1/chat/completions (Caused by ProxyError(‘Cannot connect to proxy.’, NewConnectionError(‘: Failed to establish a new connection: [WinError 10061] 由于目标计算机积极拒绝,无法连接。’)))
首先,在对短文本进行概念化时,由于实体的歧义性或KBs中的噪声,容易引入一些不恰当的概念。例如,在短文本S2:“Alice has been using Apple for 10 more years”中,从KB中获取了Apple的fruit和mobile phone两个概念。显然,fruit在这里不是一个合适的概念,这是由于Apple的模糊性造成的。
其次,需要考虑概念的粒度和概念的相对重要性。例如,在短文本S3:“Bill Gates is one of the co-founders of Microsoft”中,从KB中检索了person和entrepreneur of Bill Gates的概念。虽然它们都是正确的概念,但企业家比人更具体,在这种情况下应该被赋予更大的权重。之前的工作利用网络规模的KBs来丰富短文本表示,但没有仔细解决这两个问题。
为了解决这两个问题,该文引入注意力机制,提出了基于知识驱动注意力的深度短文本分类(STCKA)。注意力机制被广泛用于获取向量的权重,在许多NLP应用中,包括机器翻译、摘要生成和问答。针对第一个问题,使用面向短文本的概念注意力(Concept towards Short Text,CST)来衡量短文本与其对应概念之间的语义相似度。该模型赋予S2中mobile phone概念较大的权重,因为它与短文本的语义相似度高于fruit概念。针对第二个问题,使用面向概念集的注意力(Concept towards Concept Set,C-CS)来探索每个概念相对于整个概念集的重要性。模型为S3中的概念企业家分配了更大的权重,这对特定的分类任务更具区分性。
classifier("We are very happy to show you the Transformers library.")
输出:[{'label': 'POSITIVE', 'score': 0.9998}]
如果有多个输入,将输入作为列表传递给pipeline(),返回一个字典列表:
results = classifier(["We are very happy to show you the Transformers library.", "We hope you don't hate it."])
for result in results:
print(f"label: {result['label']}, with score: {round(result['score'], 4)}")
输出:
label: POSITIVE, with score: 0.9998
label: NEGATIVE, with score: 0.5309
pipeline()也可以遍历整个数据集,执行任何喜欢的任务。对于这个例子,选择自动语音识别任务:
import torch
from transformers import pipeline
speech_recognizer = pipeline("automatic-speech-recognition", model="facebook/wav2vec2-base-960h")
result = speech_recognizer(dataset[:4]["audio"])
print([d["text"] for d in result])
输出:['I WOULD LIKE TO SET UP A JOINT ACCOUNT WITH MY PARTNER HOW DO I PROCEED WITH DOING THAT', "FODING HOW I'D SET UP A JOIN TO HET WITH MY WIFE AND WHERE THE AP MIGHT BE", "I I'D LIKE TOY SET UP A JOINT ACCOUNT WITH MY PARTNER I'M NOT SEEING THE OPTION TO DO IT ON THE AP SO I CALLED IN TO GET SOME HELP CAN I JUST DO IT OVER THE PHONE WITH YOU AND GIVE YOU THE INFORMATION OR SHOULD I DO IT IN THE AP AND I'M MISSING SOMETHING UQUETTE HAD PREFERRED TO JUST DO IT OVER THE PHONE OF POSSIBLE THINGS", 'HOW DO I THURN A JOIN A COUNT']
pt_batch = tokenizer(
["We are very happy to show you the Transformers library.", "We hope you don't hate it."],
padding=True,
truncation=True,
max_length=512,
return_tensors="pt",
)
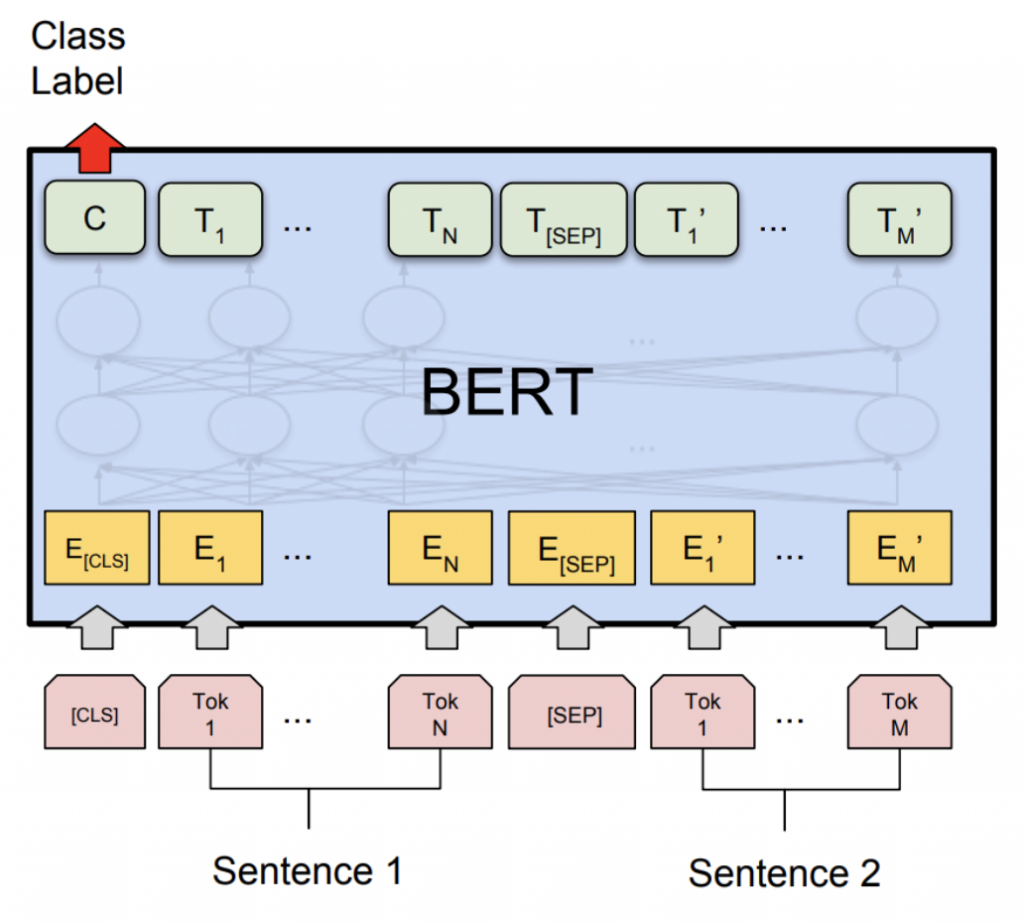
在通用语言理解评估基准(GLUE)中的Microsoft Research Paraphrase Corpus (MRPC) task上展示了准确性和推理性能结果。MRPC (Dolan and Brockett, 2005)是一个自动从在线新闻源中提取的句子对语料库,并配有人工标注,以判断句子对中的句子是否语义等价。由于类别是不平衡的(正样本为68%,负样本为32%),通常的做法是使用F1指标评估。MRPC是语言对分类的一个常见NLP任务,如下图所示。