前言
论文:https://arxiv.org/abs/2108.06332
代码:https://github.com/zhouj8553/FlipDA
背景和挑战
大多数以前的文本数据增强方法都局限于简单的任务和弱基线。作者在困难任务(小样本的自然语言理解)和强基线(具有超过10亿个参数的预训练模型)上做数据增强。
在困难任务和强基线模型下,很多以前的文本数据增强方法,最多只带来边际增益,有时会大大降低性能。在许多情况下,使用数据增强会导致性能不稳定,甚至进入故障模式。
方法
作者提出了一种新的数据增强方法FlipDA,该方法联合使用生成模型和分类器来生成标签翻转数据。FlipDA的核心思想是发现生成标签翻转数据比生成标签保留数据对性能更重要。与保留原始标签的增强数据相比,标签翻转数据往往大大提高了预训练模型的泛化能力。实验表明,FlipDA在有效性和鲁棒性之间实现了很好的权衡,它在不影响其他任务的同时,极大地改善了许多任务。在小样本的设定下,有效性和鲁棒性是数据增强两个关键要求。
有效性(Effectiveness)
数据增强应该在某些特定任务上显著提高性能。
FlipDA: Automatic Label Flipping
1、在不使用数据增强的条件下,训练分类器(对预训练的模型进行微调)
2、生成标签保留和标签翻转的增强样本
首先使用完形填空模式将x和y组合成一个序列,然后随机mask一定百分比的输入的tokens。然后使用预训练的T5模型来填补空白,形成一个新的样本。如果T5不能预测出新样本的y值,删除这个样本是有益的。使用T5生成增强样本确实引入了额外的知识并减少了语法错误,但仅使用T5进行增强而不进行标签翻转和选择效果不佳。
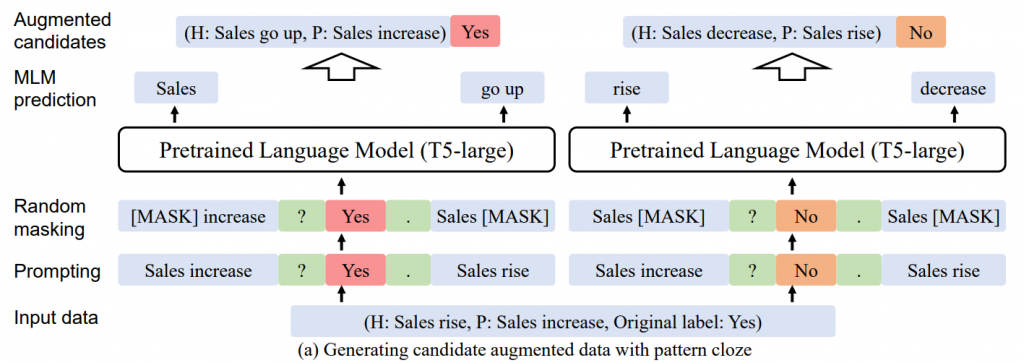
3、使用分类器为每个标签选择概率最大的生成样本
Si 是从原始样本 (xi , yi ) 增强的数据集合,y‘ 不等于 yi
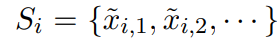
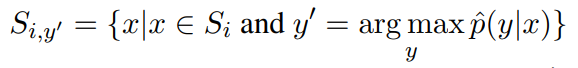
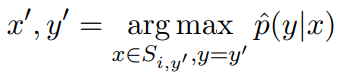
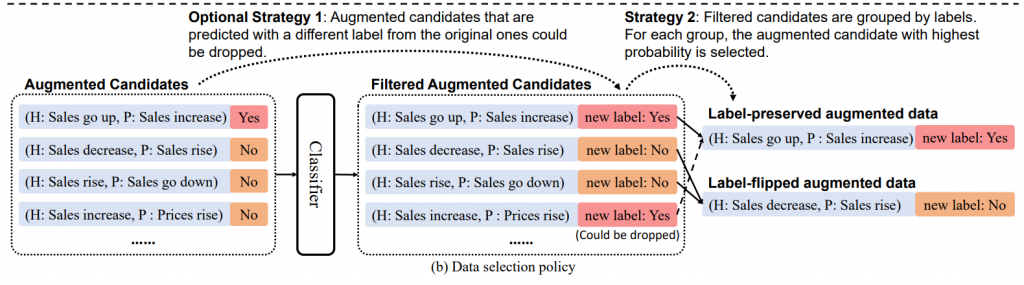
4、用原始样本和附加的增强样本重新训练分类器
鲁棒性(Robustness)
数据增强方法在任何时候不应该遇到故障模式(failure mode)。故障模式在小样本学习中很常见,在这种情况下,一些微小的更改可能会导致性能大幅下降。
What Contribute to Failure Modes?
大多数增强方法都是基于标签保留的假设,而自动方法生成标签保留的样本是一个挑战。如果模型在保持标签的假设下,在有噪声的增强数据上进行训练,性能下降是可能的。作者将噪音数据总结为两类,一类是导致理解困难的语法错误,另一类是改变标签关键信息的修改。
结论
标签翻转提高了小样本的泛化性,论文提出具有自动标签翻转和数据选择的FilpDA算法。实验证明了FlipDA的优越性,在有效性和鲁棒性方面都优于以往的方法。在未来,从理论上理解在现有数据点附近生成标签翻转数据为什么以及如何提高泛化将是至关重要的。此外,增加增强数据生成的多样性和质量也是一个重要的长期目标。
代码运行顺序
1、运行基线模型(Run Baseline)
bash scripts/run_pet.sh <task_name> <gpu_id> baseline结果会保存在results/baseline/pet/<task_name>_albert_model/result_test.txt文件中
2、产生增强的文件(Produce augmented files)
CUDA_VISIBLE_DEVICES=0 python -m genaug.total_gen_aug --task_name <task_name> --mask_ratio <mask_ratio> --aug_type <aug_type> --label_type <label_type> --do_sample --num_beams <num_beams> --aug_num <aug_num>备选方案:使用不带分类器的增强文件运行基线模型,如果希望将增强文件中的所有增强数据添加到模型中(不希望根据训练过的分类器更改标签或过滤增强样本),可以运行如下命令。
bash scripts/run_pet.sh boolq 0 <augmented_file_name>3、用增强的文件运行FlipDA(Run FlipDA with augmented files)
如果允许分类器对增广数据的标签进行校正,则执行如下命令,其中<augmented_file_name>是增强文件名,例如,”t5_flip_0.5_default_sample0_beam1_augnum10″。
bash scripts/run_pet.sh boolq 0 genaug_<augmented_file_name>_filter_max_eachla如果不允许分类器纠正增强数据的标签,则运行如下命令
bash scripts/run_pet.sh boolq 0 genaug_<augmented_file_name>_filter_max_eachla_sep选择哪个命令取决于增强模型和分类模型的relative power。如果增强模型足够精确,选择带有“sep”的命令会更好。否则,选择第一个。如果不确定,就两种都试试。