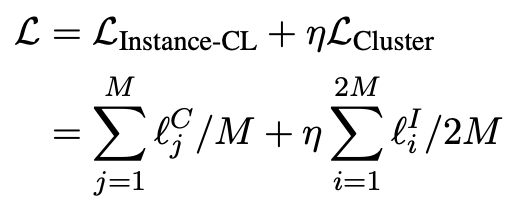论文:https://arxiv.org/pdf/2103.12953.pdf
代码:https://github.com/amazon-science/sccl
概述
无监督聚类的目的是根据在表示空间中测量的一定距离发现数据的语义类别。然而,在学习过程的开始阶段,不同的类别往往在表示空间中相互重叠,这对基于距离的聚类在实现不同类别之间的良好分离提出了重大挑战。为此,论文提出了用对比学习支持聚类(SCCL)——一个利用对比学习促进更好分离的新框架。论文实验证明SCCL在利用自底向上实例识别和自顶向下聚类的优势方面的有效性,在使用真实聚类标签进行评估时,可以获得更好的簇内和簇间距离。
即使使用深度神经网络,在聚类开始之前,数据在不同类别之间仍然存在显著重叠。因此,通过优化各种基于距离或相似度的聚类目标学习到的聚类纯度较低。
实例对比学习(Instance-CL)通常在通过数据增强获得的辅助集上进行优化。顾名思义,对比损失用于将原始数据集中同一实例的增强样本拉到一起,而将不同实例的增强样本推开。Instance-CL将不同的实例分散开来,同时在某种程度上隐式地将相似的实例聚集在一起。通过将重叠的类别分散开来,可以利用这种有益的属性来支持聚类。然后进行聚类,从而更好地分离不同的簇,同时通过明确地将该簇中的样本集中在一起,使每个簇更紧密。如图所示:
挑战
由噪声和稀疏性引起的弱信号给短文本聚类带来了重大挑战。
贡献
- 提出了一种新的无监督聚类的端到端框架,在很大程度上提高了各种短文本聚类数据集的最先进结果。此外,该模型比现有的基于深度神经网络的短文本聚类方法要简单得多,这些方法通常需要多阶段独立训练。
- 深入分析并展示了SCCL如何有效地将自上而下的聚类与自下而上的实例对比学习相结合,以实现更好的簇间距离和簇内距离。
- 本文探索了SCCL的各种文本增强技术,表明与图像域不同,在文本域使用增强的组合并不总是有益的。
SCCL模型算法
算法架构
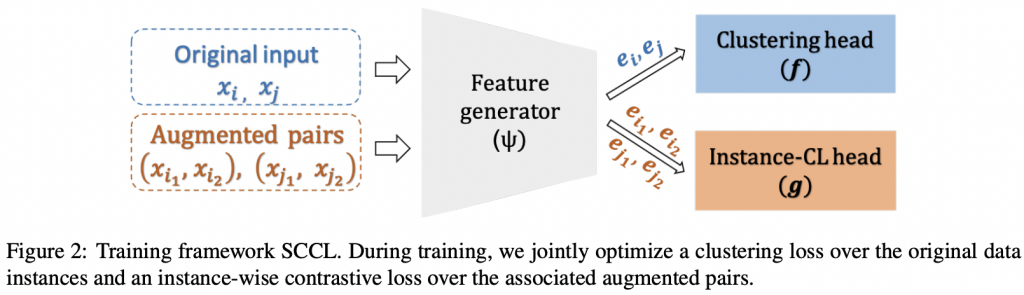
如图所示,模型由三个组件组成。神经网络ψ(·)首先将输入数据映射到表示空间,然后在表示空间中使用两个不同的头g(·)和f(·),分别应用对比损失和聚类损失。
实例级对比学习(Instance-wise Contrastive Learning)
假设在一个batch内有M个样本,每个样本增强两个样本后,增强的样本集为2M个样本,在增强的样本中,存在2个正例和2M-2个负例。对于增强的样本x1,通过最小化损失函数将样本x2区分开。zj = g(ψ(xj)), j = i1, i2
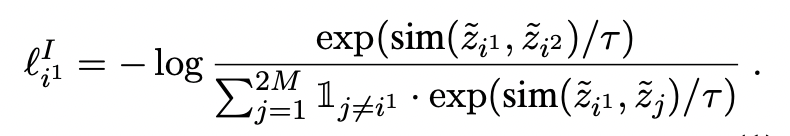
在增强后的样本集中,损失为
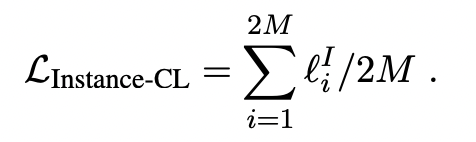
聚类
聚类这部分的算法主要来自于论文《Unsupervised Deep Embedding for Clustering Analysis》
通过无监督聚类将语义分类结构编码到表示中。与Instance-CL不同,聚类关注的是高层语义概念,并试图将同一语义类别的实例聚集在一起。
假设数据由K个语义类别组成,每个类别以其在表示空间中的质心为特征,表示为μK, K∈{1,…K}。让ej = ψ(xj)表示实例xj在原始集合B中的表示。使用学生的t分布来计算将xj分配到第k个簇的概率为
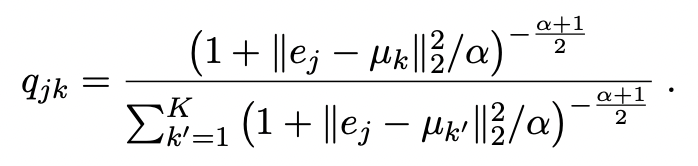
使用一个线性层,即图2中的簇头,来近似每个簇的质心,并通过利用Xie等人(2016)提出的辅助分布来迭代完善它。具体地,设pjk表示辅助概率定义为
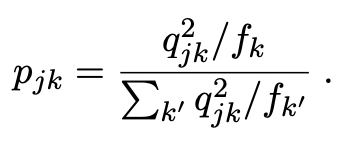
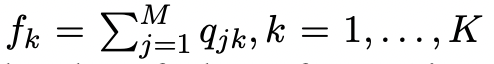
在这里,fk可以被解释为在一个minibatch内近似的软簇频率。该目标分布首先对软分配概率qjk进行2次幂锐化,然后利用相关的簇频率对其进行归一化。这样做鼓励从高置信度的聚类分配中学习,同时克服不平衡聚类造成的偏差。通过优化簇分配概率之间的KL散度,将簇分配概率推向目标分布。
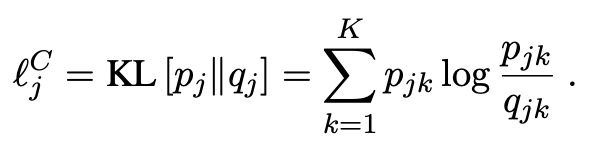
聚类的损失函数为
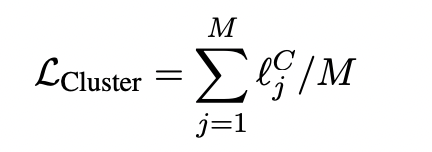
总体的目标函数为