前言
论文:https://arxiv.org/pdf/2102.12671.pdf
代码:https://github.com/lbe0613/LET
摘要
中文短文本匹配是自然语言处理中的一项基本任务。现有方法通常以汉字或词作为输入。它们有两个局限性:1)部分中文词语多义词多,语义信息没有得到充分利用;2)一些模型存在分词带来的潜在问题。该文引入HowNet作为一个外部知识库,并提出了一个语言知识增强图Transformer (LET)来处理单词歧义问题。此外,采用词格图作为输入,以维护多粒度信息。该模型还补充了预训练语言模型。在两个中文数据集上的实验结果表明,该模型优于多种典型的文本匹配方法。消融研究也表明,语义信息和多粒度信息对文本匹配建模都很重要。
挑战
- 大量的中文词语是多义词,给语义理解带来了很大的困难。短文本中的词多义现象比长文本中的词多义问题更严重,因为短文本通常具有较少的上下文信息,因此模型很难捕捉到正确的语义。
- 基于词的模型通常会遇到一些由分词引起的潜在问题
解决方法
- 为了整合词语的语义信息,引入了HowNet作为外部知识库。
- 许多研究人员提出了词格图,它保留了词库中存在的词,从而保留了不同的分词路径。研究表明,多粒度信息对于文本匹配具有重要意义。
前导知识
HowNet

HowNet是一个人工为每个汉语词义标注一个或多个相关义原的外部知识库。HowNet哲学将义原视为一个原子的语义单位。与WordNet不同,义原强调概念的组成部分和属性可以用义原很好地表示。HowNet已被广泛应用于词语相似度计算、情感分析、词语表示学习和语言建模等自然语言处理任务中。图2给出了一个例子。“苹果”这个词有两个意思,包括苹果品牌和苹果。苹果品牌有五个义原,分别是computer、PatternValue、able、bring和SpecificBrand,这五个义原描述了sense的确切含义。
阅读更多:论文笔记:LET: Linguistic Knowledge Enhanced Graph Transformer for Chinese Short Text Matching模型架构
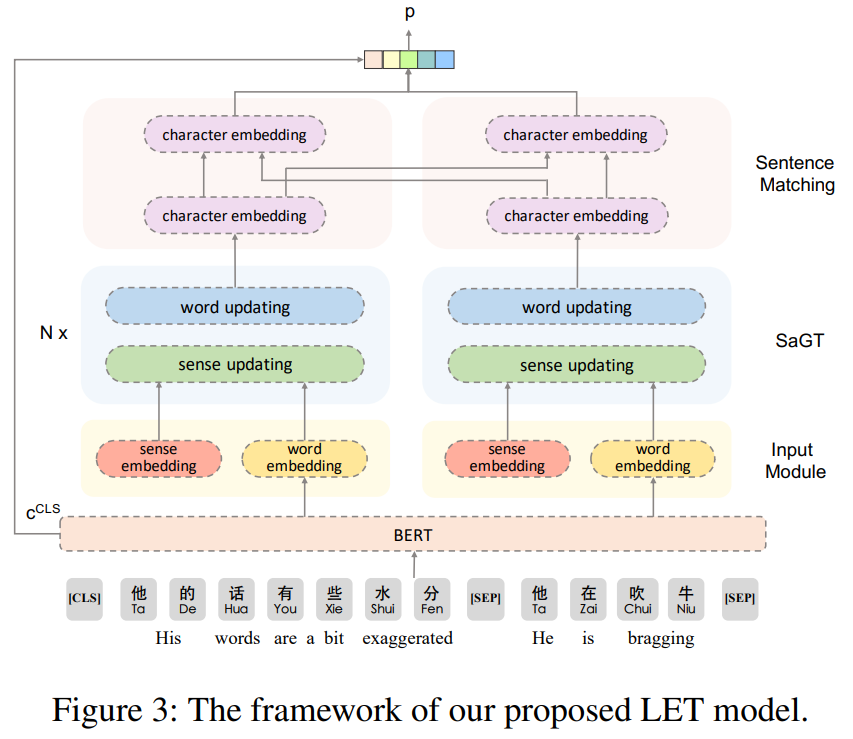
LET由4部分组成:输入模块、语义感知图转换器(SaGT)、句子匹配层和关系分类器。输入模块输出每个单词wi的初始上下文表示和每个词义的初始语义表示。SaGT迭代更新单词表示和语义表示,并融合彼此的有用信息。句子匹配层首先将词表示融入字符级,然后利用双边多视角匹配机制对两个字符序列进行匹配。关系分类器将句子向量作为输入,预测两个句子之间的关系。
输入模块
Contextual Word Embedding
上下文词嵌入对于图中的每个节点xi,单词wi的初始表示是上下文字符表示的注意力池化。假设单词wi由一些连续的字符tokens{ct1, ct1+1,···,ct2} 组成,对于每个字符ck (t1≤k≤t2),用一个两层的前馈网络(FFN)计算一个基于特征的得分向量,然后用基于特征的多维softmax (MD-softmax)进行归一化。
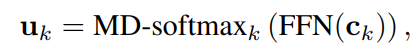
将对应的字向量ck与归一化得分uk进行加权,得到上下文词向量。
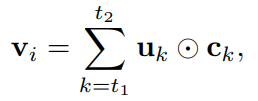
使用Att-Pooling(·)将公式7和公式8重写为:
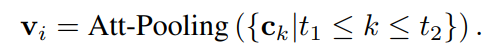
Sense Embedding
上述的词嵌入vi只包含上下文字符信息,在中文中可能会出现多义词的问题。该文采用HowNet作为外部知识库来表示词语的语义信息。
对于每个单词wi,将词义集合表示为S (wi) = {si,1, si,2,···,si,K}。si,k是wi的第k个义原,表示其对应的义原为O(si,k)。为了得到每个义项si,k的嵌入向量,首先得到每个义原的多维注意力表示:
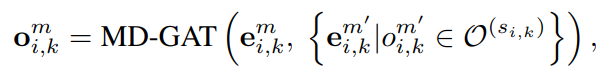
其中e是义原o的嵌入向量,由义原注意力目标模型(SAT)产生。然后,对于每个义原si,k,其嵌入通过对所有义原表示的注意力池化得到:
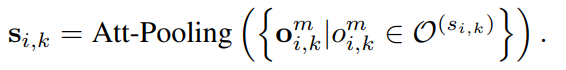
Semantic-aware Graph Transformer
对于图中的每个节点xi,词嵌入vi只包含上下文信息,而义原嵌入si,k只包含语言知识。为了从彼此中获取有用的信息,论文提出了SaGT。首先以vi和si,k分别作为单词wi的初始词表示hi和词义初始义表示gi,k,然后分两步迭代更新它们。
更新Sense Representation
对于多义的词,应该用哪个义通常是由句子中的上下文语境决定的。因此,在更新表示时,每个词义将首先从xi的前向和后向聚合单词的有用信息。
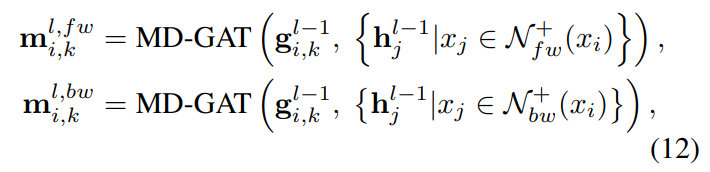
其中两个多维注意力函数MD-GAT(·)具有不同的参数。
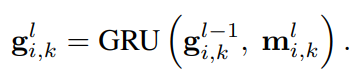
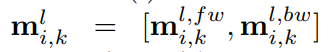
[·,·]表示向量的拼接,值得注意的是,没有直接使用mi,k作为新表示gi,k。原因是mi,k只包含上下文信息,需要利用一个门,例如GRU,来控制上下文信息和语义信息的融合。
更新Word Representation
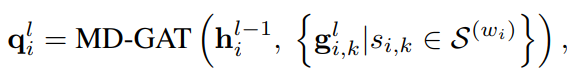
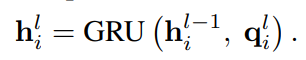
经过多次迭代,最终的词表示不仅包含上下文单词信息,还包含语义知识。对于每个句子,使用hai和hbi分别表示最终的单词表示。
句子匹配层(Sentence Matching Layer)
在获取了每个句子的语义知识增强的词表示后,将这些词信息融合到字符中。
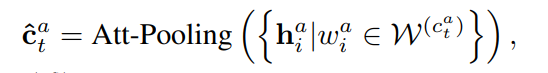
从而得到语义知识增强的字符表示yt

其中LayerNorm(·)表示层规范化,cat是使用BERT获得的上下文字符表示。对于每个字符cat ,利用多维注意力分别从句子Ca和Cb中聚合信息。

上述多维注意力函数MD-GAT(·)共享相同的参数。通过这种共享机制,该模型具有一个很好的特性,即当两个句子完全匹配时有:
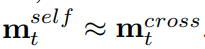
我们利用多角度余弦距离进行比较:
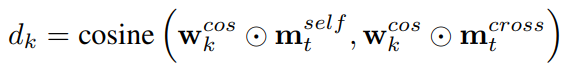
通过P个距离d1、d2、···、dP,可以得到最终的字符表示
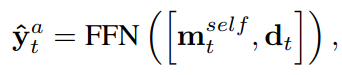
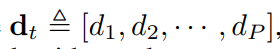
最终的字符表示包含三种信息:上下文信息、词义知识和字符级相似度。对于每个句子Ca或Cb,使用句子所有最终字符表示的注意力池化得到句子表示向量ra或rb。
Relation Classifier
模型将预测两个句子的相似度:
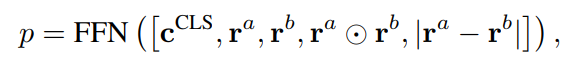
其中FFN(·)是一个前馈网络,有两个隐藏层,在输出层之后有一个sigmoid激活。训练目标是最小化二元交叉熵损失:
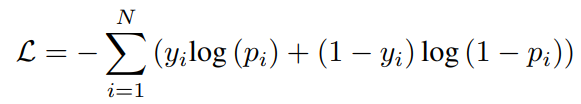
数据集
- LCQMC是一个大规模开放域问句匹配语料库。该系统由260068个中文句子对组成,其中训练样本238766个,验证样本8802个,测试样本12500个。每一对都有一个二值标签,表示两个句子是否具有相同的含义或共享相同的意图。正样本比负样本多30%。
- BQ是一个面向特定领域的大规模银行问句匹配语料库。该系统由12万对汉语句子对组成,包括100000个训练样本、10000个验证样本和10000个测试样本。每一对还与一个二进制标签相关联,该标签表示两个句子是否具有相同的含义。正样本和负样本的数量相同。
结论
本文提出了一种新的linguistic knowledge enhanced graph transformer,用于中文短文本匹配。该模型以两个词格图作为输入,融合了HowNet中的语义信息,以缓解词的歧义性。所提方法在两个中文基准数据集上进行了评估,获得了最好的性能。消融研究还表明,语义信息和多粒度信息对文本匹配建模都很重要。
