论文:https://arxiv.org/pdf/2109.08678.pdf
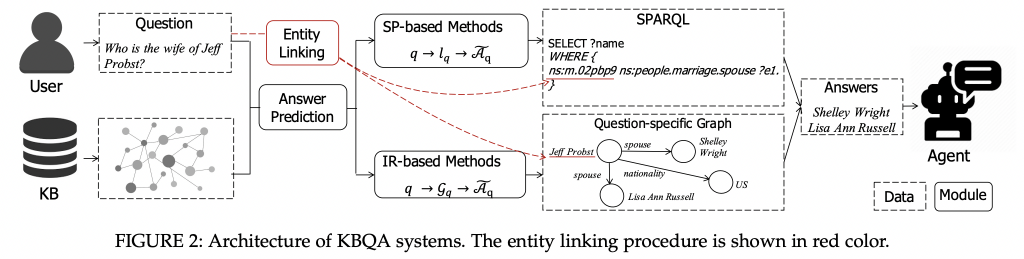
整体架构
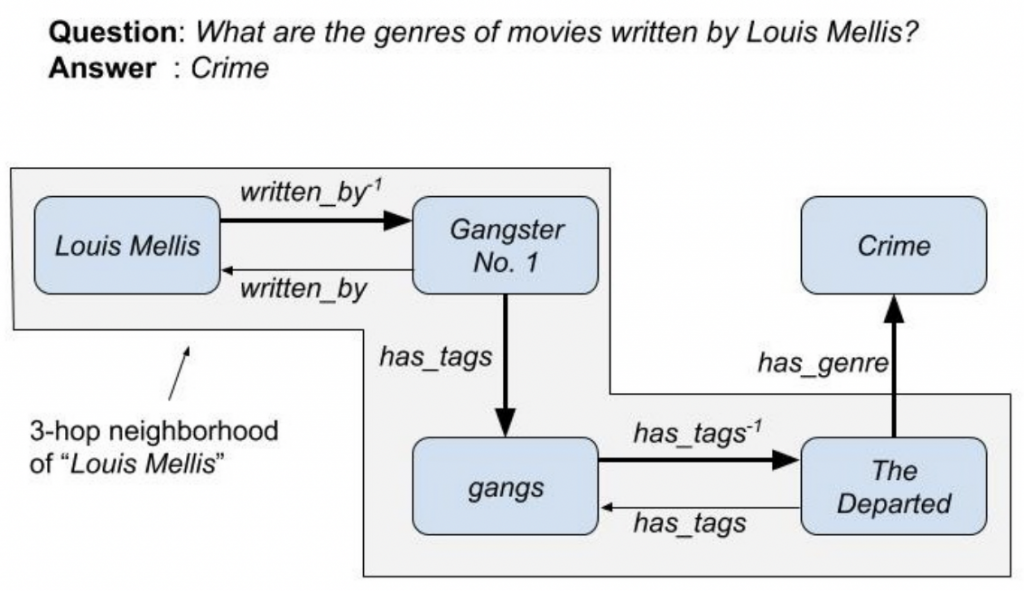
Enumeration of Candidates
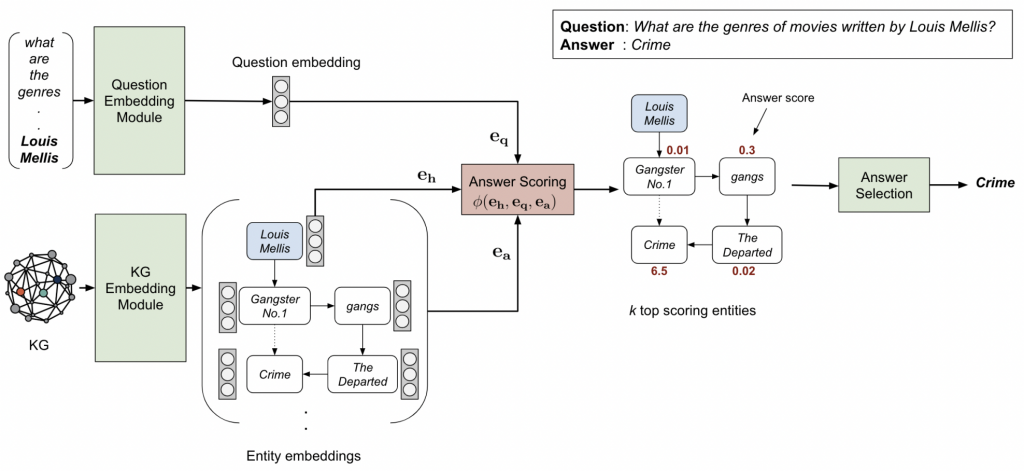
Logical Form Ranking
排名器是基于BERT双编码器(以输入问题-候选对作为输入)经过训练,以最大限度地提高基本事实逻辑形式的分数,同时最大限度地减少不正确候选者的分数。
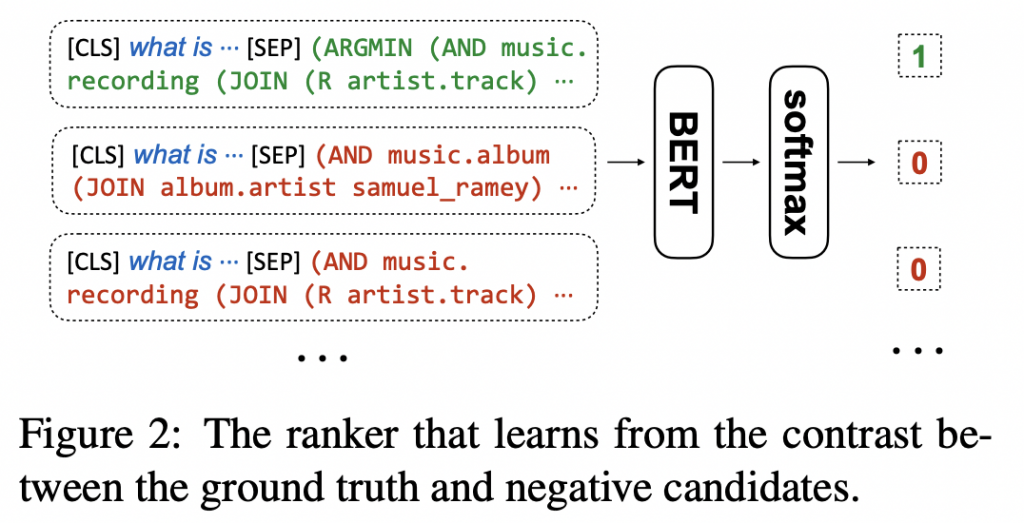
扩展了提出的逻辑形式排序器,保持架构和逻辑相同,用于实体消歧任务,并展示其作为第二阶段实体排序器的有效性。
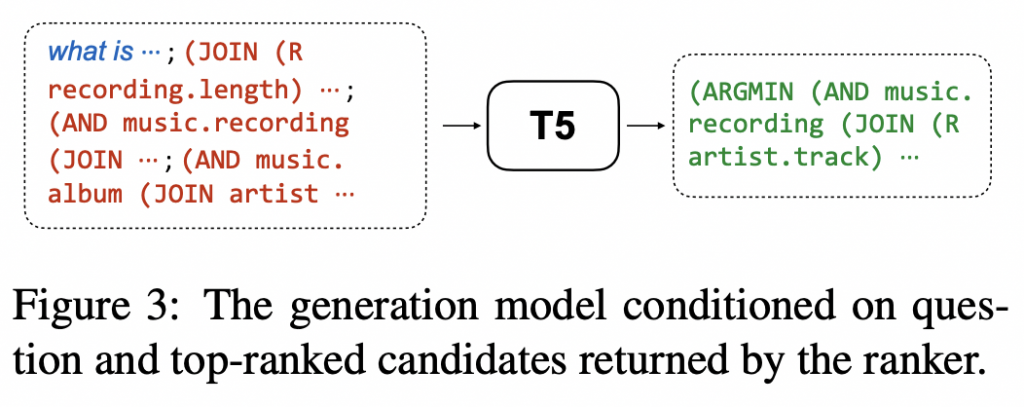
Target Logical Form Generation
有了候选的排名列表,引入了一个生成模型来组成以问题为条件的最终逻辑形式和我们的排名器返回的前 k 个逻辑形式。 生成器是从 Raffel 等人实例化的基于转换器的 seq-to-seq 模型,因为它在生成相关任务中表现出强大的性能。 如图所示,通过连接问题和由分号分隔的排名器返回的前 k 个候选者(即 [x; ct1; …; ctk])来构建输入。
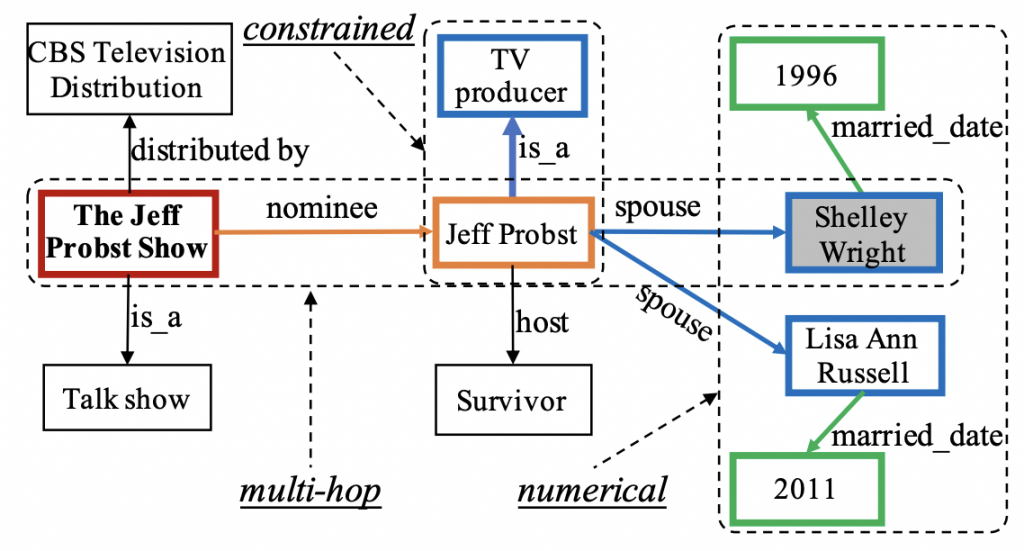
GRAILQA 是第一个评估零样本泛化的数据集。 具体来说,GRAILQA 总共包含 64,331 个问题,并仔细拆分数据,以评估 KBQA 任务中的三个泛化级别,包括 i.i.d. 设置、构图设置(泛化到看不见的构图)和零镜头设置(泛化到看不见的 KB 模式)。 我们在图中展示了组合泛化( compositional generalization )和零样本泛化( zero-shot generalization)的示例。测试集中每个设置的分数分别为 25%、25% 和 50%。 除了泛化挑战之外,GRAILQA 还存在额外的困难,包括大量涉及的实体/关系、逻辑形式的复杂组合性(最多 4 跳)以及问题中提到的实体的噪声。