前言
论文:https://arxiv.org/pdf/2210.00305v1.pdf
代码:https://github.com/zjunlp/PromptKG
概述
知识图谱(KGs)通常有两个特征:异构的图结构和文本丰富的实体/关系信息。知识图谱表示学习旨在将关系和实体映射到连续的向量空间中,从而提高知识推理能力,并可应用于问答系统、推荐系统等下游任务。知识图谱表示模型需要考虑图结构和文本语义,但目前没有一个全面的开源框架主要针对知识图谱的信息性文本描述。论文提出了一个用于知识图谱表示学习和应用的开源提示学习框架PromptKG,它装备了前沿的基于文本的方法,集成了一个新的即时学习模型,并支持各种任务(如知识图补全、知识回答、推荐和知识探究)。
一些显著的开源和长期维护的知识体系表示工具包已经开发出来,如OpenKE, LibKGE, PyKEEN, CogKGE。然而,在不使用任何辅助信息的情况下,这些基于嵌入的方法在浅层网络架构的表达能力方面受到限制。
相比之下,基于文本的方法结合可用文本进行知识表示学习。随着提示学习(prompt learning)的快速发展,大量基于文本的模型被提出,这些模型可以通过预训练语言模型获得良好的性能。
阅读更多:论文笔记:PromptKG: A Prompt Learning Framework for Knowledge Graph Representation Learning and Application基于文本的知识图谱表示
基于判别方法(Discrimination-based methods)
基于判别方法有两种模型:
一种(如KG- bert 和PKGC)利用单个编码器对带有文本描述的知识图谱三元组进行编码;
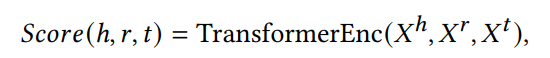
另一种(如StAR和SimKGC)利用孪生编码器(双塔模型)和预训练语言模型分别对实体和关系进行编码。

基于生成方法(Generation-based methods)
给定一个缺失尾实体的三元组(h, r, ?),给模型输入<?h, ?r>,输出?t。在训练过程中,生成模型最大化条件概率:
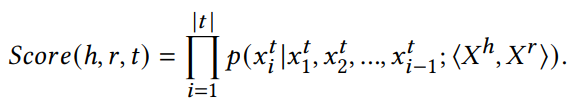
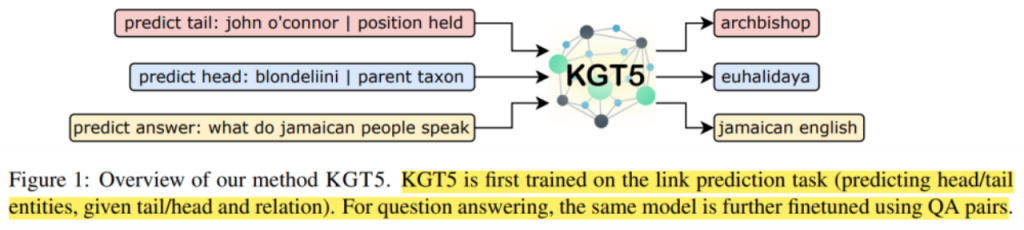
为了保证知识图谱中解码序列模式和tokens的一致性,GenKGC提出了一个实体感知的分层解码器来约束??。此外,受提示学习的启发,GenKGC采用与样例相同关系的三元组隐式编码结构化知识。此外,KGT5提出用文本描述对知识图谱表示进行预训练。
基于提示学习的知识表示学习
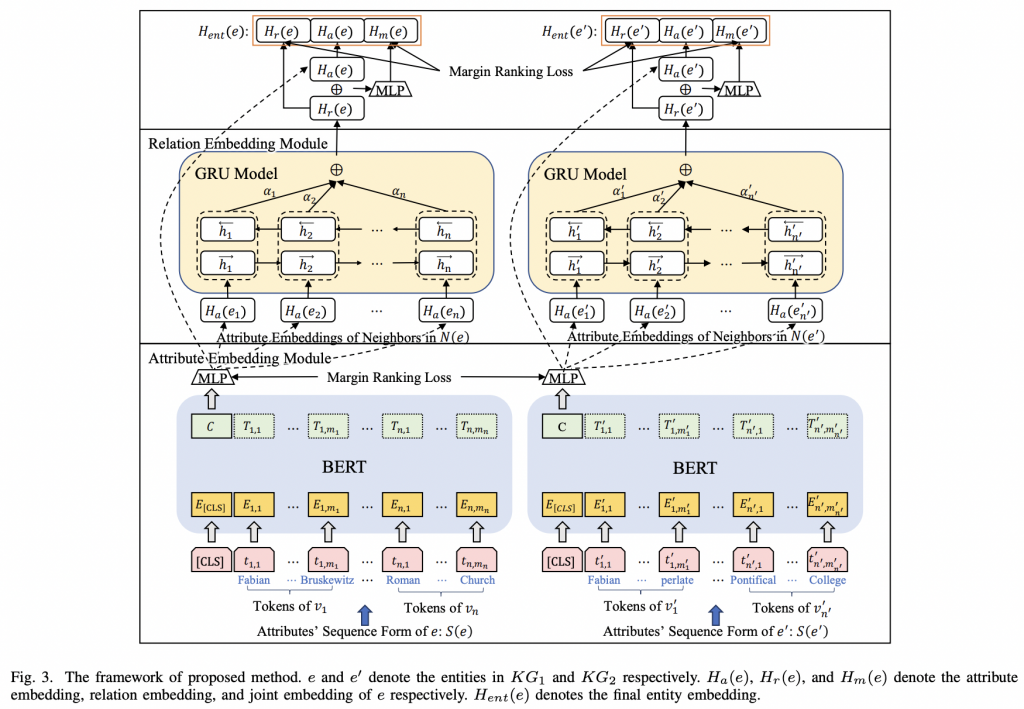
普通的预训练语言模型中有两个模块:一个用于将token id嵌入到语义空间的词嵌入层(a word embedding layer),另一个用于生成上下文感知嵌入的编码器(encoder)。该方法与普通的判别式方法共享相同的架构。论文采用掩码语言模型,在词嵌入层将实体和关系视为特殊标记。如图所示,该模型利用头部实体和关系及其描述的序列预测出正确的尾部实体。对于实体/关系嵌入,冻结编码器层(encoder),只微调实体嵌入层(entity embedding),以优化损失函数:
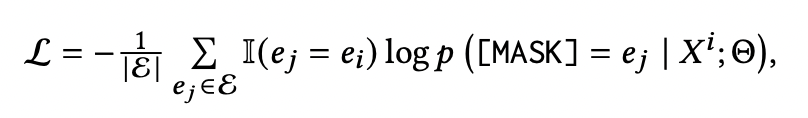
其中Θ表示模型的参数,?? 和 ?? 是实体?的描述和嵌入。
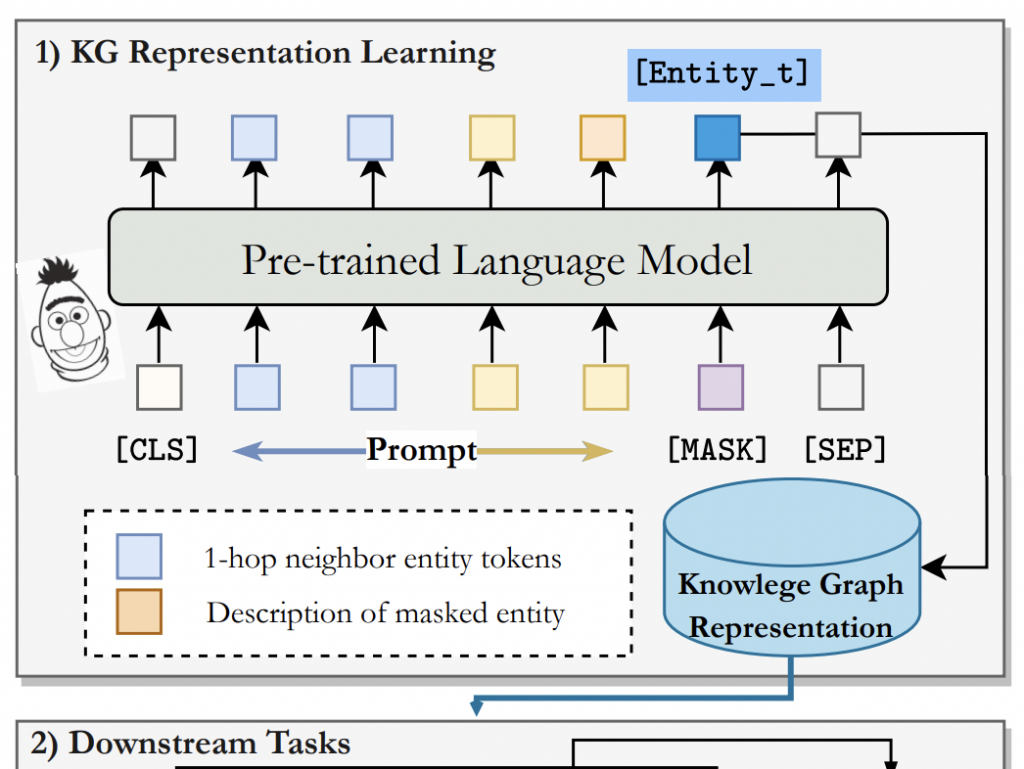
PromptKG整体结构
PromptKG的设计原则
1)统一的知识图谱编码器:PromptKG利用统一的编码器封装图结构和文本语义;
2)模型枢纽:PromptKG集成了许多前沿的基于文本的KG表示模型;
3)灵活的下游任务:PromptKG将KG表示学习和下游任务进行了解耦
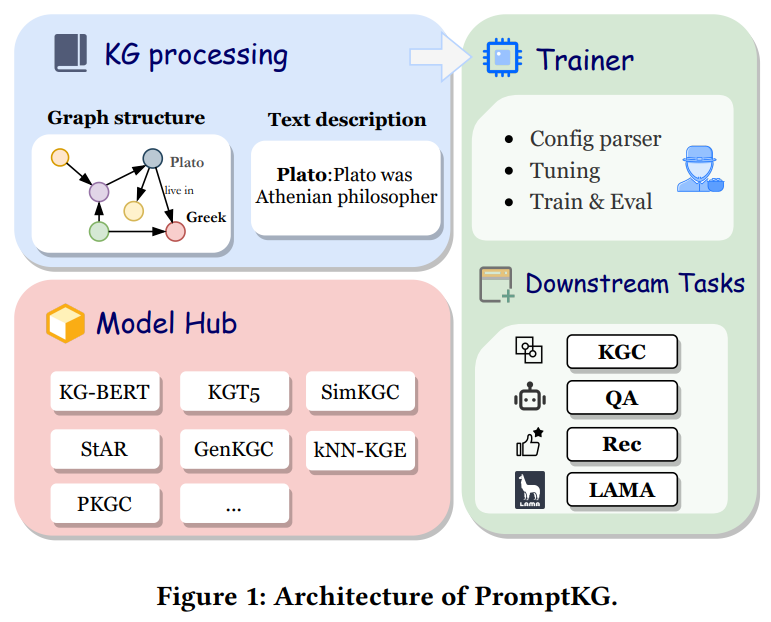
统一的知识图谱编码(Unified KG Encode)
一个统一的知识图谱编码器表示图结构和文本语义,支持不同类型的基于文本的知识图谱表示方法。
对于基于判别的方法,输入是建立在纯文本描述上的:
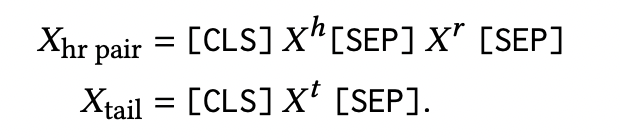
对于基于生成的模型,利用 ?ℎ 和 ?? 中的来优化带有标签 ?? 的模型。当预测头实体时,在输入序列中添加一个特殊的token( [reverse])以进行反向推理。用特殊的tokens表示知识图谱中的实体和关系,并得到如下输入:

其中,[Entity h]表示头实体的特殊token。为编码图结构,对1跳邻居实体进行采样,并将它们连接起来作为隐式结构信息的输入。
通过统一的知识图谱编码器,PromptKG可以编码异构的图结构和丰富的文本语义信息。
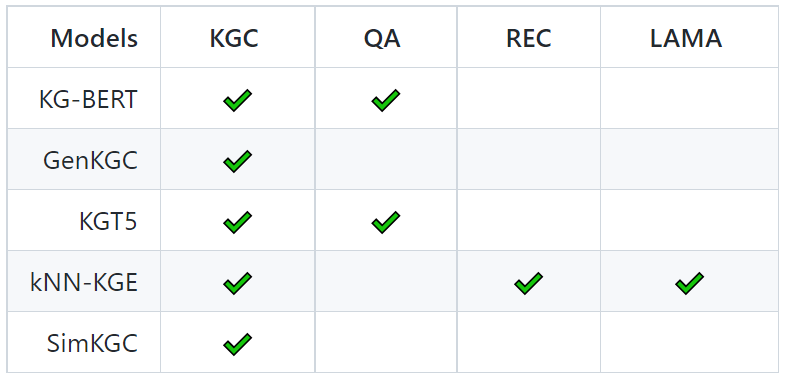
模型中心(Model Hub)
PromptKG由一个模型中心组成,支持许多基于文本的知识图谱表示模型。例如,KG-BERT使用BERT对三元组及其描述进行评分。但KG-BERT具有较高的时间复杂度,StAR和SimKGC都引入了一种基于塔的方法( a tower-based method)来预计算实体嵌入并高效地检索top-?实体。此外,GenKGC和KGT5将知识图谱补全视为序列到序列(seq2seq)的生成方法。此外,?NN-KGE是一种通过k近邻线性插值其实体分布的知识图谱表示模型。
应用到下游任务(Applying to Downstream Task)
以基于提示学的知识图谱表示学习为例,如下图所示:
- 对于知识图谱补全,向模型输入头实体和关系的文本信息⟨?ℎ,??⟩,然后通过掩码token预测获得目标尾实体。
- 对于问答,向模型输入用自然语言编写的问题,并将其与[MASK] token连接起来,以获得目标答案(实体)的特殊token。
- 在推荐方面,将用户的交互历史作为实体嵌入的顺序输入,然后利用掩码token预测来获得推荐项目。
- 对于知识探测任务,采用实体嵌入作为额外的知识,以帮助模型更好地通过句子进行推理,并预掩码位置的token,遵循PELT。

Entity_t指不同任务的目标尾实体、答案实体、推荐项目和目标尾实体,它遵循预训练(获得嵌入)和微调范式(特定任务调优)。
实验结果
1)基于文本信息的知识图谱补全(链接预测)是知识图谱表示的直接下游任务;
2)问答是一种直观的知识密集型任务;
3)推荐涉及与真实世界知识图谱中的实体对齐,因此可以从知识图谱表示中受益;
4)知识探究(LAMA)利用完形问句分析语言模型中包含的事实知识和常识知识。
知识补全(Knowledge Graph Completion)
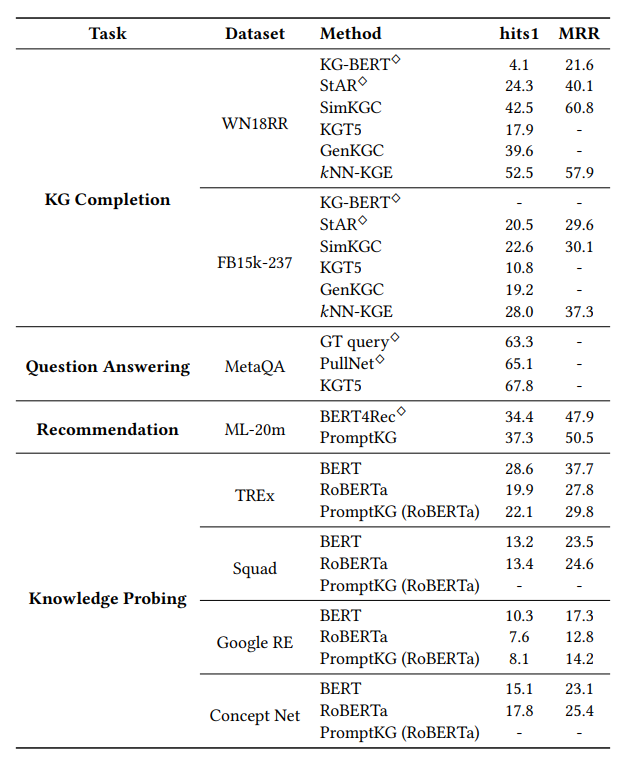
针对知识图谱补全任务,论文在数据集WN18RR和FB15k-237上进行了链接预测实验,并在PromptKG上使用hits1和MRR指标对模型进行了评估。从表中,基于判别的方法SimKGC比其他基线模型取得了更高的性能。KGT5和GenKGC等基于生成的模型也产生了可比较的结果,并显示了知识图谱表示的潜在能力。?NN-KGE可以从知识存储中通过计算最近邻居实体嵌入空间的距离和两步训练策略的来获得最佳hits1分数。
知识问答(Question Answering)
将PromptKG应用于问答系统,并在MetaQA数据集上进行实验。由于计算资源的限制,论文只评估了1跳推断性能。从表中可以看出,PromptKG中的KGT5具有最佳性能。
知识推荐(Recommendation)
对于推荐任务,在一个完善的版本ML-20m上进行了实验。利用ML-20m与KB4Rec提供的Freebase的链接,获取ML-20m中电影的文本描述。在这些描述上预训练电影嵌入后,按照BERT4Rec的设置在顺序推荐任务上进行了实验。与BERT4Rec相比,PromptKG被证实是有效的推荐。
知识探索(Knowledge Probing)
知识探索检查语言模型(BERT、RoBERTa等)召回事实的能力。使用预训练BERT (BERT -base-uncase)和RoBERTa (RoBERTa -base)模型在LAMA上进行实验。为证明由知识图谱增强的实体嵌入有助于语言模型从预训练中获取更多事实知识,训练了一个遵循PELT的可插拔实体嵌入模块。
如表所示,当使用实体嵌入模块时,性能有所提高。由于Squad中没有标注的主题实体,Concept Net中也没有对应主题实体的URI进行实体对齐,因此只对LAMA中的剩余数据进行实体嵌入。
结论
论文提出PromptKG,一种知识图谱表示学习和应用的提示学习框架。PromptKG建立了一个统一工具包,该工具包具有定义明确的模块和易于使用的接口,以支持在知识图谱上使用PLMs的研究。PromptKG为研究人员和开发人员提供有效和高效的训练代码,并支持下游任务。