论文:https://arxiv.org/pdf/2108.06688.pdf
这篇论文是复杂KBQA方面的一篇综述。介绍了复杂 KBQA 的两大主流方法,即基于语义解析( semantic parsing-based, SP-based)的方法和基于信息检索(information retrieval-based, IR-based)的方法。从这两个类别的角度回顾了先进的方法并解释了对典型挑战的解决方案。
论文动机
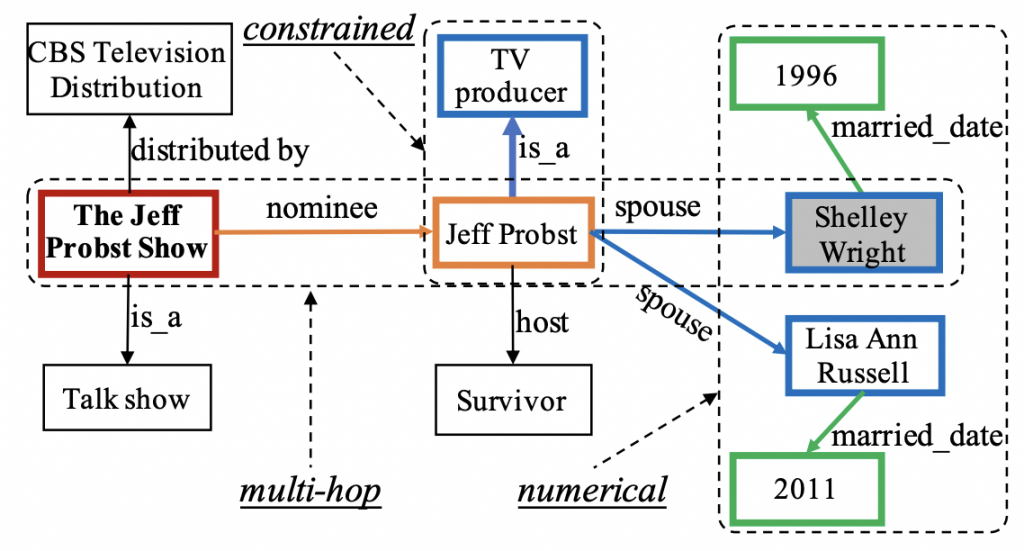
Who is the first wife of TV producer that was nominated for The Jeff Probst Show?
- 在知识图谱中做多跳推理 (multi-hop reasoning)
- 考虑题目中给的限制词 (constrained relations)
- 考虑数字运算的情况 (numerical operations)
知识图谱问答系统思路
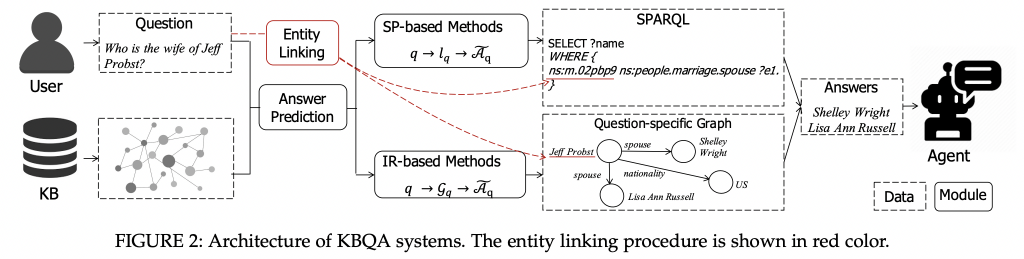
- 实体连接 (entity linking),识别问题q的主题实体eq,其目的是将问题链接到知识库中的相关实体。在这一步中,进行命名实体识别、消歧和链接。通常使用一些现成的实体链接工具来完成,例如 S-MART、DBpediaSpotlight和 AIDA;
- 利用答案预测模块来预测答案 Aq。可以采用以下两种方法进行预测:
- 基于语义解析 (SP-based) 方法:将问题解析为逻辑形式,并针对知识库执行以找到答案;
- 基于信息检索 (IR-based) 方法:检索特定于问题的图并应用一些Rank算法从顶部位置选择实体。
- 最后,将 KBQA 预测得到的预测答案 Aq 作为系统输出返回给用户
遇到的挑战
直接将传统知识图谱问答模型运用到复杂问题上,不管是基于语义解析的方法还是信息检索的方法都将遇到新的挑战:
- 传统方法无法支撑问题的复杂逻辑:
- 现有的 SP-based 的方法中使用的解析器难以涵盖各种复杂的查询(例如,多跳推理、约束关系和数值运算)。
- 以前的 IR-based 的方法可能无法回答复杂的查询,因为它们排名是在没有可追溯推理的情况下对小范围实体进行的。
- 复杂问题包含了更多的实体,导致在知识图谱中搜索空间变大:这两种方法都将问题理解视为首要步骤。当问题在语义和句法方面变得复杂时,模型需要具有强大的自然语言理解和泛化能力。
- 通常 Complex KBQA 数据集缺少对正确路径的标注:这表明 SP-based 的方法和 IR-based 的方法必须分别在没有正确逻辑形式和推理路径注释的情况下进行训练。这种微弱的监督信号给这两种方法带来了困难。